
# 线程池
# 常用的线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
内部ThreadPoolExecutor的全量入参构造:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
2
3
4
5
6
7
- corePoolSize:核心线程数;
- maximumPoolSize:最大线程数;
- keepAliveTime:超过corePoolSize时,多余部分的存活时间;
- unit:存活时间单位;
- workQueue:任务队列,保存提交但未执行的任务;
- threadFactory:线程工厂;
- handler:拒绝策略。
三种常见的线程池:
| 方法名称 | 使用的队列 | 队列类型 | 功能 |
|---|---|---|---|
| FixedThreadPool | LinkedBlockingQueue | 无界队列 | 创建固定大小的线程池,corePoolSize和maximumPoolSize相等,使用无界队列LinkedBlockingQueue,过多的任务将会导致队列Runnable元素过多而造成内存溢出 |
| SingleThreadExecutor | LinkedBlockingQueue | 无界队列 | 创建只有一个线程的线程池,corePoolSize和maximumPoolSize都为1 |
| CachedThreadPool | SynchronousQueue | 直接提交队列 | 创建一个没有容量的线程池,任何提交的任务都会立即执行(复用线程或者创建线程),corePoolSize为0,maximumPoolSize为无穷,容易创建线程过多导致内存溢出 |
队列类型:
- 直接提交队列:SynchronousQueue,没有容量,无缓冲等待队列,不存储元素,会将任务交给消费者,容易达到线程最大值和执行拒绝策略,没有存放元素的能力,针对每一个take操作都会阻塞到put的执行;
- 有界队列:ArrayBlockingQueue和有capality的LinkedBlockingQueue,能够容纳队列容量的峰值线程;
- 无界队列:无capality(即Integer.MAX_VALUE)的LinkedBlockingQueue,没有容量,永远不会执行拒绝策略,任务很多时会造成内存溢出。
内部源码实现:
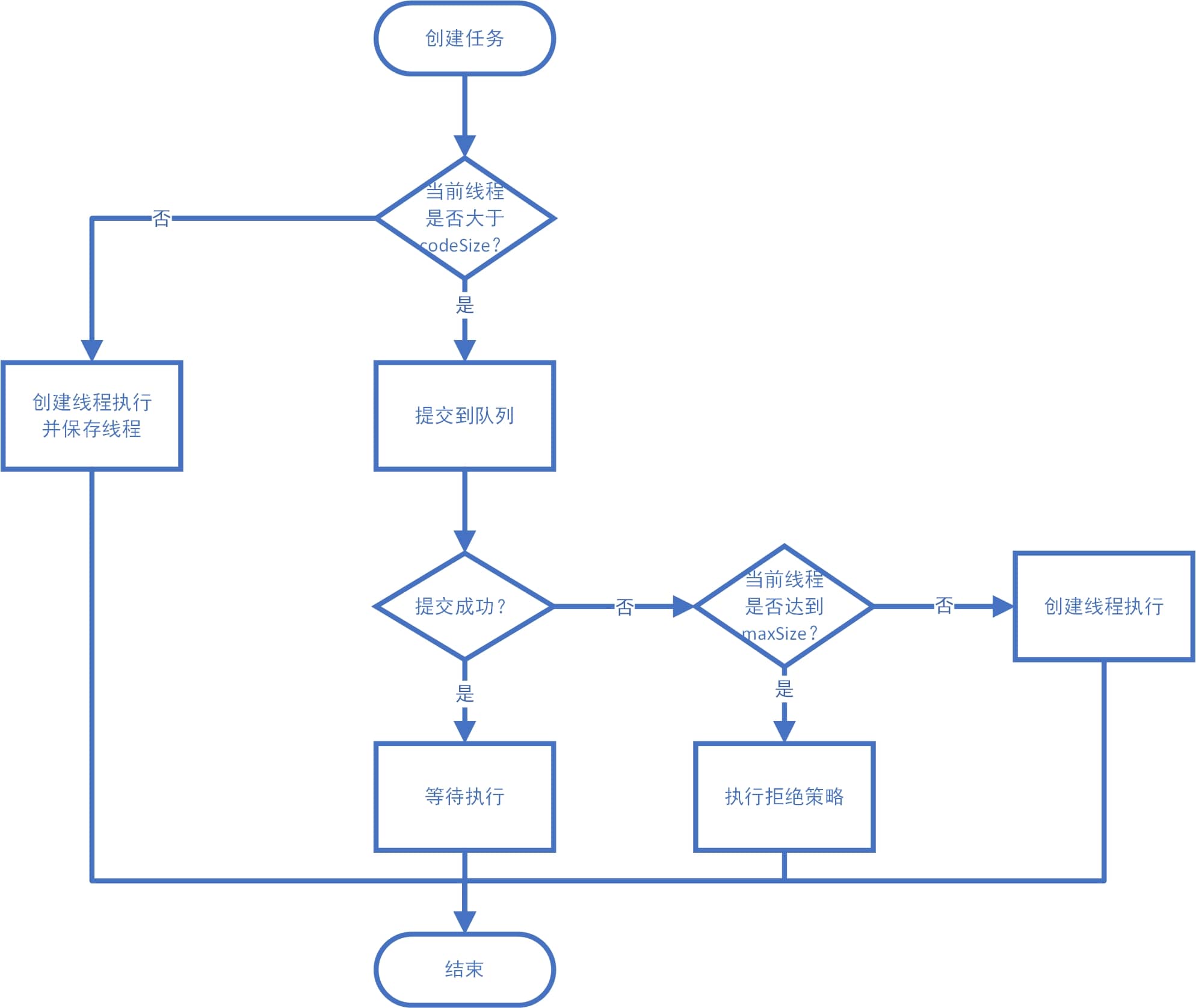
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//如果当前线程数量小于核心线程数
if (workerCountOf(c) < corePoolSize) {
//添加worker并执行对应的任务
if (addWorker(command, true))
return;
c = ctl.get();
}
//把当前任务扔入队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//如果当前threadpool不在运行中,删除对应的任务
if (!isRunning(recheck) && remove(command))
//执行拒绝策略
reject(command);
else if (workerCountOf(recheck) == 0)
//增加至少一个执行器
addWorker(null, false);
}
//如果入队失败,则尝试新增执行器直接执行任务
else if (!addWorker(command, false))
//添加执行器失败,执行拒绝策略
reject(command);
}
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get();
if (runStateOf(c) != rs)
continue retry;
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//新建执行器
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
//执行器运行
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
private static final long serialVersionUID = 6138294804551838833L;
final Thread thread;
Runnable firstTask;
volatile long completedTasks;
Worker(Runnable firstTask) {
setState(-1);
this.firstTask = firstTask;
//在threadpool中的threadfactory中创建执行的线程
this.thread = getThreadFactory().newThread(this);
}
public void run() {
//本质上调用runWorker方法执行
runWorker(this);
}
protected boolean isHeldExclusively() {
return getState() != 0;
}
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock();
boolean completedAbruptly = true;
try {
//注意此处循环调用getTask方法,按照getTask的结果判断下次是否需要继续执行
while (task != null || (task = getTask()) != null) {
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
private Runnable getTask() {
boolean timedOut = false;
//进行CAS操作
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
//判断是否需要跳出
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
//如果当前线程数比核心线程数还大
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
//此处控制worker是否需要继续存活,按照队列的超时获取功能或者阻塞功能实现
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
常用的提交方法:
- execute:会抛出异常,抛出异常后线程线程直接死亡,不会存放到线程池中;
- submit:内部捕获异常,异常保存在成员变量中,在FutureTask.get阻塞获取时候把异常抛回来,抛出异常后线程仍然进入线程池。
拒绝策略:
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
public static class AbortPolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException();
}
}
public static class DiscardPolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
- CallerRunsPolicy:直接在提交任务的线程中执行任务;
- AbortPolicy:直接报错处理;
- DiscardPolicy:静默处理;
- DiscardOldestPolicy:抛弃最旧(准备执行)的任务并且再次提交任务。
常用的计划任务线程池:
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize){
return new ScheduledThreadPoolExecutor(corePoolSize);
}
2
3
4
5
6
7
8
常用的执行计划任务接口:
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit);
2
3
4
5
6
7
8
9
- scheduleAtFixedRate:以一定的速率执行,不管上一个任务有没有执行完毕;
- scheduleWithFixedDelay:以固定的延时执行,上一个任务执行完后x秒再执行。
# 线程的6种状态
public class Thread implements Runnable {
public enum State {
//新建
NEW,
//就绪,可执行
RUNNABLE,
//阻塞
BLOCKED,
//等待(无时限)
WAITING,
//等待(有时限)
TIMED_WAITING,
//结束
TERMINATED;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
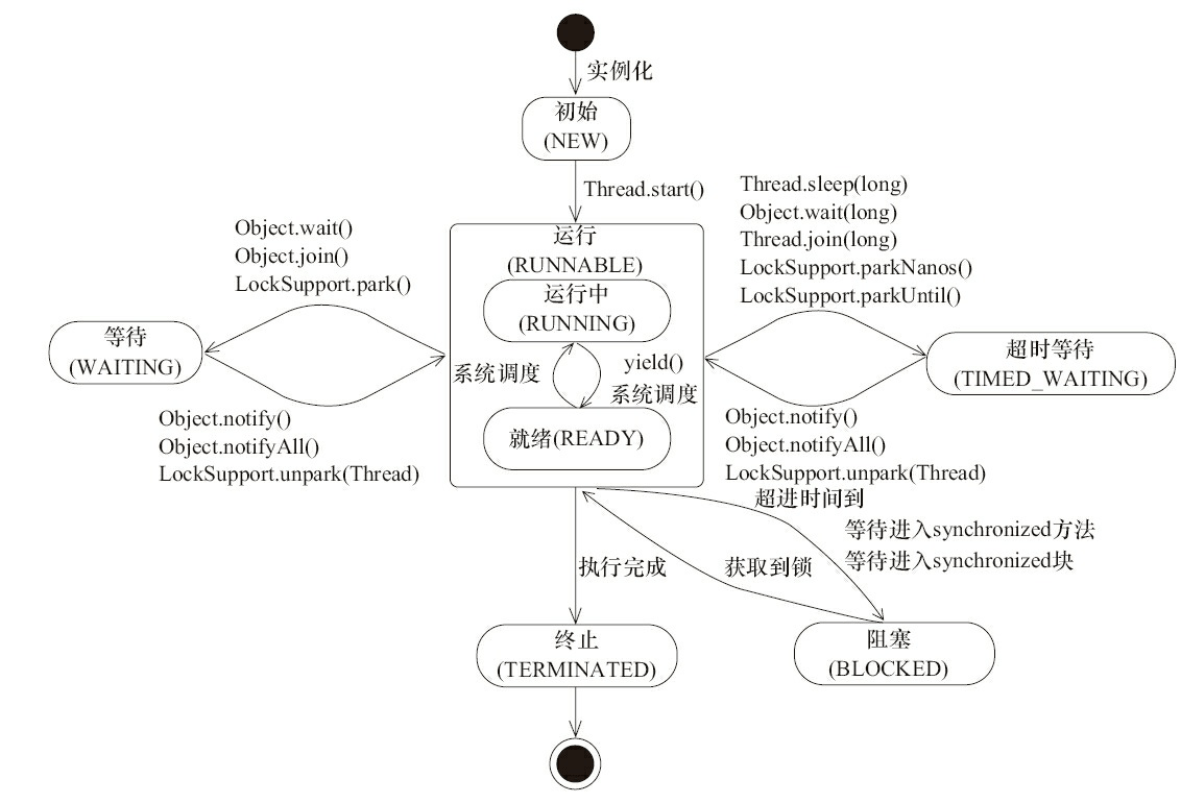
RUNNABLE是指等待运行和运行中的集合状态:在Thread.start()执行后,线程就可以被CPU接纳执行;
WAITING指无时限的等待,TIMED_WAITING指无时限的等待;
yield()操作指CPU放弃对当前线程的执行权,重新让线程进行资源争夺;
join()指当前线程等待某个线程执行完成才能继续执行;
sleep()让指定时间内暂停执行,但不会释放锁;
wait()在使用时需要对监视对象进行synchronized。
# 线程池的高级用法
# 全局任务
如果有重要的任务,执行多次的效果是幂等的(执行1000次和执行1次的效果一样),那么建议用全局任务的方式创建线程
new ThreadPoolExecutor(
1,
1,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(1),
runnable -> new Thread(runnable, "whole-job-thread"),
(r, executor) -> log.info("drop trigger event!, normally you can ignore this message~")
)
2
3
4
5
6
7
8
9
# 组件线程的控制
往往很多组件都内置了自己的线程,此时业务无需多此一举再关心线程的控制,因为控制不好反而会发生OOM,例子:在kafka监听消息的入口,无需再开启新的线程控制,原因是kafka已经内置线程管理;若自己添加线程介入,可能kafka处理任务比业务线程快导致任务的积压。
private static final ExecutorService EXECUTOR_SERVICE = new ThreadPoolExecutor(
Runtime.getRuntime().availableProcessors() + 1,
Runtime.getRuntime().availableProcessors() + 1,
0L,
TimeUnit.MILLISECONDS,
// 注意这里用无界队列吧
new LinkedBlockingQueue<>(),
(ThreadFactory) Thread::new
);
/**
* 监听点击事件入口
* 这里入口为纯写新的数据内容,可以不做更改
*
* @param records 记录
*/
@KafkaListener(topics = "${kafka.topic.click}", containerFactory = HIIDO_KAFKA_LISTENER_CONTAINER_FACTORY)
public void listenClick(List<ConsumerRecord<String, String>> records) {
// 这里开启线程
EXECUTOR_SERVICE.execute(() -> {
for (ConsumerRecord<String, String> record : records) {
try {
HiidoClickReq hiidoClickReq = OBJECT_MAPPER.readValue(record.value(), HiidoClickReq.class);
List<HiidoClickDetailReq> hiidoClickDetailReqs = Optional.ofNullable(hiidoClickReq.getDatas()).orElse(Collections.emptyList());
for (HiidoClickDetailReq hiidoClickDetailReq : hiidoClickDetailReqs) {
if (StringUtils.isBlank(hiidoClickDetailReq.getArgs())) {
continue;
}
Map<String, String> content = decodeArgs(hiidoClickDetailReq.getArgs());
Optional
.of(content)
.map(abstractClickParamConverter::convert)
.filter(checker::checkClick)
.ifPresent(clickService::save);
}
} catch (Exception e) {
log.error("listen click event error: ", e);
}
}
});
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
正确应该是:
/**
* 监听点击事件入口
* 这里入口为纯写新的数据内容,可以不做更改
*
* @param records 记录
*/
@KafkaListener(topics = "${kafka.topic.click}", containerFactory = HIIDO_KAFKA_LISTENER_CONTAINER_FACTORY)
public void listenClick(List<ConsumerRecord<String, String>> records) {
for (ConsumerRecord<String, String> record : records) {
try {
HiidoClickReq hiidoClickReq = OBJECT_MAPPER.readValue(record.value(), HiidoClickReq.class);
List<HiidoClickDetailReq> hiidoClickDetailReqs = Optional.ofNullable(hiidoClickReq.getDatas()).orElse(Collections.emptyList());
for (HiidoClickDetailReq hiidoClickDetailReq : hiidoClickDetailReqs) {
if (StringUtils.isBlank(hiidoClickDetailReq.getArgs())) {
continue;
}
Map<String, String> content = decodeArgs(hiidoClickDetailReq.getArgs());
Optional
.of(content)
.map(abstractClickParamConverter::convert)
.filter(checker::checkClick)
.ifPresent(clickService::save);
}
} catch (Exception e) {
log.error("listen click event error: ", e);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 线程
# CountDownLatch和CycleBarrier
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(3, new ThreadFactory() {
private AtomicInteger ai = new AtomicInteger();
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "线程" + ai.getAndIncrement());
}
});
CountDownLatch countDownLatch = new CountDownLatch(3);
for (int i = 0; i < 3; i++) {
executorService.execute(() -> {
System.out.println(Thread.currentThread().getName() + "正在执行中");
try {
Thread.sleep(3000L);
countDownLatch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
countDownLatch.await();
System.out.println("主线程执行完毕");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
线程0正在执行中
线程1正在执行中
线程2正在执行中
主线程执行完毕
2
3
4
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newCachedThreadPool(new ThreadFactory() {
private AtomicInteger ai = new AtomicInteger();
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "线程" + ai.getAndIncrement());
}
});
CyclicBarrier cyclicBarrier = new CyclicBarrier(2, new Runnable() {
private AtomicInteger ai = new AtomicInteger();
@Override
public void run() {
System.out.println("=====我现在是在" + Thread.currentThread().getName() + "执行=====");
System.out.println("第" + ai.getAndIncrement() + "次开始");
}
});
for (int i = 0; i < 5; i++) {
executorService.execute(() -> {
System.out.println(Thread.currentThread().getName() + "正在执行中");
try {
cyclicBarrier.await();
Thread.sleep(3000L);
System.out.println(Thread.currentThread().getName() + "执行完毕");
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
});
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
线程0正在执行中
线程1正在执行中
=====我现在是在线程1执行=====
第0次开始
线程2正在执行中
线程3正在执行中
=====我现在是在线程3执行=====
第1次开始
线程4正在执行中
线程2执行完毕
线程0执行完毕
线程1执行完毕
线程3执行完毕
2
3
4
5
6
7
8
9
10
11
12
13
CountDownLatch
- 主线程调用await方法睡眠,子线程调用countDown方法减少计数值,当计数值到达0,则自动唤醒主线程继续执行;
- 不可以重复使用,仅使用一次
- 本质上是使主线程继续执行
CycleBarrier
- 子线程调用await减少计数值,当计数值到达0,则触发对应的Runnable的动作
- 可以重复使用
- 本质上是在使计数变为0的线程中执行Runnable动作
# 线程的中断
interrupt():通过运行的线程实例,给线程发送中段信号,仅仅设置线程的中断标志位,并没有额外的其余操作,至于如何处理中段响应需要看被中断的线程的实际处理逻辑
- 如果线程是正常运行中,且没有判断中段状态,那么线程就会一直执行
/** * 线程执行3秒后并没有停止运行 */ private static void runNoStop() throws InterruptedException { Thread thread = new Thread(() -> { while (true) { System.out.println("我还在运行中"); } }); thread.start(); Thread.sleep(3000L); thread.interrupt(); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15我还在运行中 我还在运行中 我还在运行中 我还在运行中 我还在运行中 我还在运行中 我还在运行中 我还在运行中1
2
3
4
5
6
7
8- 如果线程被阻塞,那么线程会被抛出InterruptedException中段异常
/** * 响应InterruptedException中段异常 */ private static void runWithBlockAndStop() throws InterruptedException { Thread thread = new Thread(() -> { while (true) { System.out.println("我还在运行中"); try { Thread.sleep(2000L); } catch (InterruptedException e) { System.out.println("我被中断了"); return; } } }); thread.start(); Thread.sleep(3000L); thread.interrupt(); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21我还在运行中 我还在运行中 我被中断了1
2
3- 如果线程是正常运行中,可以通过isInterrupted()判断自身的中段标记位
/** * 响应中段标记位,不清除中断标记位 */ private static void runWithCheckInterruptWithoutClear() throws InterruptedException { Thread thread = new Thread(() -> { while (true) { if (Thread.currentThread().isInterrupted()) { System.out.println("我被中段了"); break; } else { System.out.println("我还在运行中"); } } System.out.println("当前线程中断标志位:" + Thread.currentThread().isInterrupted()); }); thread.start(); Thread.sleep(3000L); thread.interrupt(); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21我还在运行中:777445 我还在运行中:777446 我被中段了 我被中段了 我被中段了 我被中段了1
2
3
4
5
6isInterrupted():查询线程的中断标记位,具体用法见安上文样例
interrupted():与isInterrupted()不同的是,这个方法是静态方法,调用后会查询并且清除中断标记位
/**
* 响应中段标记位,并且清除中断标记位
*/
private static void runWithCheckInterruptAndClear() throws InterruptedException {
Thread thread = new Thread(() -> {
while (true) {
if (Thread.interrupted()) {
System.out.println("我被中段了");
break;
} else {
System.out.println("我还在运行中");
}
}
System.out.println("当前线程中断标志位:" + Thread.currentThread().isInterrupted());
});
thread.start();
Thread.sleep(1000L);
thread.interrupt();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
我还在运行中
我还在运行中
我还在运行中
我还在运行中
我还在运行中
我被中段了
当前线程中断标志位:false
2
3
4
5
6
7
# LockSupport工具
正常使用方法:
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
System.out.println("---------- 被阻塞进程执行 ----------");
LockSupport.park();
System.out.println("---------- 被阻塞进程结束 ----------");
});
thread.start();
Thread.sleep(2000L);
LockSupport.unpark(thread);
System.out.println("释放了阻塞线程");
}
2
3
4
5
6
7
8
9
10
11
12
---------- 被阻塞进程执行 ----------
释放了阻塞线程
---------- 被阻塞进程结束 ----------
2
3
对应的LockSupport内置一个许可
- 许可在默认情况下没有许可,因此调用LockSupport.park()时默认会阻塞
- 许可最多有一个,使用unpark()后给予线程一个许可,连续多次unpark()效果是一样的
- 对于LockSupport.park(),它不会抛出InterruptedException,但是它也是响应中断的,若park时被中断,则会从LockSupport.park()下一行处继续执行,此时的中断标记位为true
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
try {
Thread.sleep(5000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("---------- 被阻塞线程执行 ----------");
LockSupport.park();
System.out.println("---------- 被阻塞线程结束 ----------");
});
thread.start();
LockSupport.unpark(thread);
System.out.println("释放了阻塞线程");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
释放了阻塞线程
---------- 被阻塞线程执行 ----------
---------- 被阻塞线程结束 ----------
2
3
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
try {
Thread.sleep(5000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("---------- 被阻塞线程执行 ----------");
LockSupport.park();
System.out.println("第一次消费许可");
LockSupport.park();
System.out.println("第二次消费许可");
System.out.println("---------- 被阻塞线程结束 ----------");
});
thread.start();
LockSupport.unpark(thread);
LockSupport.unpark(thread);
System.out.println("释放了阻塞线程");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
释放了阻塞线程
---------- 被阻塞线程执行 ----------
第一次消费许可
2
3
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
System.out.println("---------- 被阻塞进程执行 ----------");
LockSupport.park();
System.out.println("被阻塞线程的中断标记位:" + Thread.currentThread().isInterrupted());
System.out.println("---------- 被阻塞进程结束 ----------");
});
thread.start();
Thread.sleep(2000L);
thread.interrupt();
System.out.println("释放了阻塞线程");
}
2
3
4
5
6
7
8
9
10
11
12
13
---------- 被阻塞进程执行 ----------
释放了阻塞线程
被阻塞线程的中断标记位:true
---------- 被阻塞进程结束 ----------
2
3
4
# 序列化与反序列化
- 原生的JVM进行序列化和反序列化对象时需要实现Serializale接口,若被序列化的对象没有实现该接口,或者成员变量中含有引用类型但没实现该接口,则抛出NotSerializableException异常;
- Serializale本质上来说是个空接口,需要开发人员覆盖serialVersionUID字段,JVM在反序列化的时候校验这个字段是否一致;
- 使用时机:想把一个对象保存在一个文件或者数据库中,或者想通过RMI传输对象的时候。
# IO与NIO的区别与代码样例分析
| IO(传统的IO) | NIO | |
|---|---|---|
| 面向对象 | 面向流 | 面向缓冲 |
| 是否阻塞 | 阻塞IO | 非阻塞IO |
| 实现方式 | 数组 | Buffer |
| 客户端个数:IO线程数 | 1:1 | M:1 |
public class TestNIO {
public static void main(String[] args) {
MultiplexerTimeServer multiplexerTimeServer = new MultiplexerTimeServer(10222);
new Thread(multiplexerTimeServer, "hahahahahah").start();
}
static final class MultiplexerTimeServer implements Runnable {
private Selector selector;
private ServerSocketChannel serverSocketChannel;
private volatile boolean stop;
public MultiplexerTimeServer(int port) {
try {
selector = Selector.open();
serverSocketChannel = ServerSocketChannel.open();
//设置为非阻塞式
serverSocketChannel.configureBlocking(false);
serverSocketChannel.socket().bind(new InetSocketAddress(port), 1024);
//注册channel
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
} catch (IOException e) {
e.printStackTrace();
}
}
public void stop() {
this.stop = true;
}
@Override
public void run() {
while (!stop) {
try {
selector.select(1000);
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
SelectionKey key = null;
while (iterator.hasNext()) {
key = iterator.next();
iterator.remove();
try {
handleInput(key);
} catch (Exception e) {
if (key != null) {
key.cancel();
if (key.channel() != null) {
key.channel().close();
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
if (selector != null) {
try {
selector.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
private void handleInput(SelectionKey key) throws IOException {
if (key.isValid()) {
if (key.isAcceptable()) {
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
SocketChannel accept = channel.accept();
accept.configureBlocking(false);
accept.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel channel = (SocketChannel) key.channel();
ByteBuffer byteBuffer = ByteBuffer.allocate(10);
int bytes = channel.read(byteBuffer);
if (bytes > 0) {
byteBuffer.flip();
byte[] bs = new byte[byteBuffer.remaining()];
byteBuffer.get(bs);
System.out.println("收到报文为:" + new String(bs, StandardCharsets.UTF_8));
doWrite(channel, "我是相应报文");
} else if (bytes < 0) {
key.cancel();
channel.close();
}
}
}
}
private void doWrite(SocketChannel channel, String response) throws IOException {
if (response != null && response.trim().length() > 0) {
byte[] bytes = response.getBytes();
ByteBuffer byteBuffer = ByteBuffer.allocate(bytes.length);
byteBuffer.put(bytes);
byteBuffer.flip();
channel.write(byteBuffer);
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
# 基础
# equals()、==、hashCode()和System.identityHashCode区别
- equals比较的是程序员自定义的两个对象比较的方法,相不相等自己实现,约定重写equals必须重写hashcode;
- ==比较的是两个对象的内存地址是否相等;
- hashCode可以通过重写自定义对象的哈希值计算方式,而System.identityHashCode则是判断两个对象原生的hashcode(和内存地址相关的计算方式),无论这个对象hashCode是否被重写,因此System.identityHashCode可以直接判断两个对象是否内存相等(例如判断String是否内存相等)。
# String
# String、StringBuilder、StringBuffer的联系与区别
- String天生是不可变的,因此是线程安全的;
- StringBuilder是可以变的,但线程不安全;
- StringBuffer是可以变的,线程安全。
# intern()方法以及各种String方式引用易错点
Jdk1.6以前
- 如果常量池存在该字面量的字符串,返回这个常量池对象的引用;
- 在常量池不存在,则创建与字面量一样的字符串,返回常量池(新建)对象的引用;
Jdk1.7及以后
- 如果常量池存在该字面量的字符串,返回这个常量池对象的引用(同1.6);
- 在常量池不存在,在常量池中记录首次出现的实例引用,并返回这个引用;
public static void main(String[] args) {
String s1 = new String("a") + new String("bc");
String s2 = "abc";
String s3 = new String("ab") + new String("c");
System.out.println("s1:" + System.identityHashCode(s1));
System.out.println("s1.intern():" + System.identityHashCode(s1.intern()));
System.out.println("s2:" + System.identityHashCode(s2));
System.out.println("s3:" + System.identityHashCode(s3));
System.out.println("s3.intern():" + System.identityHashCode(s3.intern()));
}
2
3
4
5
6
7
8
9
10
11
s1:1956725890
s1.intern():356573597
s2:356573597
s3:1735600054
s3.intern():356573597
2
3
4
5
- String s = "test",直接使用字符串常量创建字符串,则在常量池中创建;
- String s = new String("test"),先在常量池中创建test字符串常量,并返回在堆上的new String("test")的实例引用;
- String s = "te" + "st",在常量池中创建"te"、"st"和"test",并返回"test"在常量池中的引用;
- String s = new String("te") + new String("st"),在常量池中创建"te","st",并在堆上创建字面量为"test"的对象并返回堆上引用。
# 为什么使用字符数组保存密码比使用String保存密码更好
- String在java中是不可变的,字符串放在常量池中,直到执行GC才会被清除,任何能够访问内存的人都能直接看到密码,非常不安全;
- 使用字符串在进行文本输出时,会存在风险,能够直接打印出来,但是字符数组打印的是对应的内存数组。
# String如何实现对象不可变
- String类使用final修饰,子类无法对该类进行方法的重写;
- 内部的字符数组使用final修饰,本质上无法变更其指向;
- 内部所有的方法均返回一个新的String对象实例。
# 锁
# wait、notify和notifyAll的使用
- 使用前必须获取锁对象的监视器,即需要进行synchronized上锁;
- notify和notifyAll的区别是,notify去随机唤醒监视器队列中的一个等待线程,而notifyAll是唤醒全部线程,但是仍然需要进行等待处理(等待获取锁)。
# volatile关键字的作用
- 保证可见性:保证对所有的线程可见,标记volatile的字段,在写操作时,会强制刷新cpu缓存,标记volatile的字段,每次读取都是直接读内存;
- 保证有序性:在volatile写操作前插入StoreStore屏障,在写操作后插入StoreLoad屏障;在volatile读操作前插入LoadLoad屏障,在读操作后插入LoadStore屏障,禁止了指令的重排。
# Lock、tryLock和lockInterruptibly有什么区别
- lock:线程一直在等待锁,不然一直都会在block的状态,不响应interrupt中断;
- tryLock:马上返回,拿到锁就返回true,否则返回false;
- lockInterruptibly:响应interrupt中断,并要求处理InterruptExcetpion。
# AQS的实现原理
# 数据结构部分
AbstractQueuedSynchronizer的实现是CLH的变体,CLH本质上是一个不进行阻塞,后节点不断轮询前节点状态的虚拟队列;CLH适合用于低竞争,并发量少的场景,如果线程多,可能会导致CPU不断地空转,因此要解决这个问题就需要对线程状态进行控制,即不要让线程空轮询等待,而是让其进行挂起。
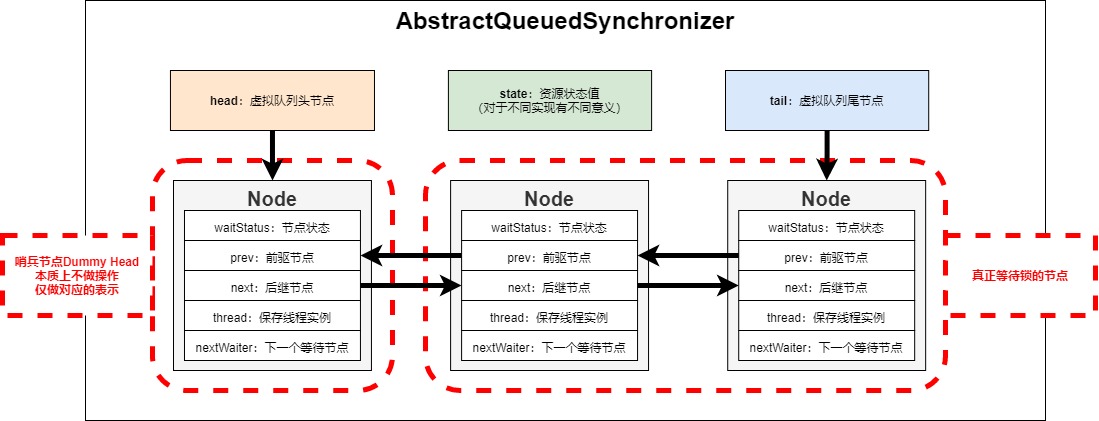
public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable {
static final class Node {
/**
* 共享模式初始值
*/
static final Node SHARED = new Node();
/**
* 独占模式初始值
*/
static final Node EXCLUSIVE = null;
/**
* 当前等待的线程被取消
*/
static final int CANCELLED = 1;
/**
* 后继节点等待被唤醒
*/
static final int SIGNAL = -1;
/**
* 当前节点线程在等待condition中
*/
static final int CONDITION = -2;
/**
* 需要被广播唤醒
*/
static final int PROPAGATE = -3;
/**
* 节点的状态,表示上面的几个状态
*/
volatile int waitStatus;
/**
* 当前节点的前驱节点
*/
volatile Node prev;
/**
* 当前节点的后继节点
*/
volatile Node next;
/**
* 保存的线程实例
*/
volatile Thread thread;
/**
* 等待condition的节点,因为只有在独占的模式下才能使用condition
* 因此这个值仅针对独占才有意义的,用一个特殊值来表示共享模式
* 在独占模式下:初始为空
* 在共享模式下:初始为SHARED
*/
Node nextWaiter;
}
/**
* CLH的头节点
*/
private transient volatile Node head;
/**
* CLH的尾节点
*/
private transient volatile Node tail;
/**
* 当前的状态值
* 针对于不同的实现有不同的意义逻辑
* 简单而言通过这个state值的简单CAS控制着整个AQS的可用状态
*/
private volatile int state;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
Node数据结构:
- waitStatus:表示节点的状态
- CANCELLED:当前节点等待的线程被取消
- SIGNAL:后继节点等待被唤醒
- CONDITION:当前节点线程在等待队列中
- PROPAGATE:当前节点线程等待被广播
- prev:当前节点的前驱节点
- next:当前节点的后继节点
- thread:挂起的线程实例对象
- nextWaiter:等待condition的节点,仅在独占模式下才有用
- SHARED:默认new了一个节点
- EXCLUSIVE:为空
AbstractQueuedSynchronizer数据结构:
- head:虚拟队列头节点
- tail:虚拟队列尾节点,一般用CAS进行修改
- state:当前获取锁的状态值,这个值对于不同的实现类的意义是不一样的,这个值是微观指令在宏观的表现;正常来说,判断一个资源是否有竞争,可以直接通过CAS进行修改state的状态,判断一下是否修改成功,如果成功意思说无竞争,程序可以继续执行;如果有竞争,则需要进入等待队列了
# 代码方法块详解
# 需要重写的代码部分
比较核心的方法是:
- tryAcquire(int): boolean
- tryRelease(int): boolean
- tryAcquireShared(int): int
- tryReleaseShared(int): boolean
- isHeldExclusively(): boolean
上面的几个核心方式都是需要被子类覆盖使用的,不然都会抛出UnsupportedOperationException异常
/**
* 以独占模式尝试获取执行权
*
* @param arg 获取执行权参数
* @return 是否获得执行权
*/
protected boolean tryAcquire(int arg) {
throw new UnsupportedOperationException();
}
/**
* 以独占模式尝试释放执行权
*
* @param arg 释放执行权参数
* @return 是否完全被释放
*/
protected boolean tryRelease(int arg) {
throw new UnsupportedOperationException();
}
/**
* 以共享模式尝试获取执行权
*
* @param arg 获取执行权参数
* @return 是否获得执行权
*/
protected int tryAcquireShared(int arg) {
throw new UnsupportedOperationException();
}
/**
* 以共享模式尝试释放执行权
*
* @param arg 释放执行权参数
* @return 是否完全被释放
*/
protected boolean tryReleaseShared(int arg) {
throw new UnsupportedOperationException();
}
/**
* 是否被当前线程独占获取
*
* @return 是否被当前线程独占获取
*/
protected boolean isHeldExclusively() {
throw new UnsupportedOperationException();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# 获取执行权部分代码块
我认为,在AQS中,不应该引入“锁”这个观念,因为在锁这个概念一般是指ReentrantLock重入锁,而ReentrantLock又是以AQS进行实现的,总不能以具体的实现来理解高层次的抽象;因此我认为网文上指获取到锁是泛指的概念,应该理解为:获取到执行权更加精确
/**
* 获取执行权
* 1. 进行快速尝试获取执行权
* 2. 若快速尝试失败,则进入等待队列(相对于快速尝试,此方法属于兜底的方式)
* 若获取不到则进行无限时等待(等待前面的有执行权的线程唤醒),不响应中断异常
*
* @param arg 执行权获取参数
*/
public final void acquire(int arg) {
// 开始快速尝试获取执行权
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
// 如果进入了等待队列,并且取消挂起后,若本线程被中断了,那么立刻调用一下中断的方法以响应中断
selfInterrupt();
}
/**
* 中断自身线程
* 这里是在线程本身被中断过的时候触发
*/
static void selfInterrupt() {
Thread.currentThread().interrupt();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
- tryAcquire这个方法是需要用户进行重写的,可以理解为对执行权获取进行快速尝试,简单实现来说仅仅是对state状态进行CAS的一次操作
- 如果上述的tryAcquire执行不成功,那么就要执行acquireQueued(addWaiter(Node.EXCLUSIVE), arg));先执行addWaiter,其逻辑意义为:在等待队列中添加当前的线程节点,并且返回创建的节点;acquireQueued对新创建的节点进行同步等待获取执行权处理,其返回值代表在等待期间线程是否又被中断
- 如果acquireQueued执行返回true,那么就需要对中断进行逻辑响应处理
- 对应selfInterrupt这个方法只是简单地对当前执行线程的进行中断
/**
* 创建新的节点并且将其设置为尾节点
* 1. 创建新的节点
* 2. 把对应的节点添加到CLH队列的末尾
*
* @param mode 创建节点的模式,独占/共享
* @return 新创建的节点
*/
private Node addWaiter(Node mode) {
// 创建新的节点,并保存当前的线程实例对象
Node node = new Node(Thread.currentThread(), mode);
// -------------start-------------
// 这段代码是可有可无的,这里选择快速尝试而已
Node pred = tail;
if (pred != null) {
// 这里有个疑问是,如果compareAndSetTail执行失败不就导致设置错了么?
// 其实不会,因为如果compareAndSetTail执行失败,则会执行enq
// 在enq方法里面进行了对prev节点的重新设置
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
// -------------end-------------
enq(node);
return node;
}
/**
* 入队操作
* 1. 若CLH队列为空,则初始化
* 2. 在虚拟队列中尾部添加新的节点
*
* @param node 需要入队的节点
* @return 入队节点的前驱节点
*/
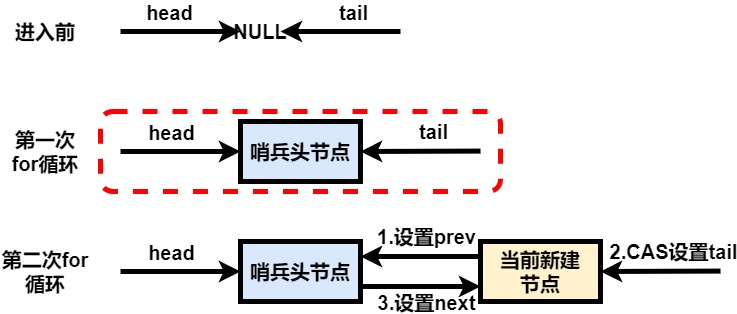
private Node enq(final Node node) {
// 自旋操作
for (; ; ) {
Node t = tail;
// 因为所有成员变量都是懒加载的,因此这里需要初始化
if (t == null) {
// 这里如果失败了,说明头已经不是空了,那么下一次的for循环操作就会进入else的代码块中
// 如果这里成功了,那么下次for循环也会引导进入下面的else代码块中
// 这里只是建立的一个虚拟的头节点(哨兵节点)
if (compareAndSetHead(new Node()))
tail = head;
} else {
// 这里很重要,在把当前节点设置为末尾节点之前,保证了当前节点的前置节点一定是尾节点
// 也就是说,当下面的compareAndSetTail执行成功前后,一定能够保证当前节点的prev指针指向前面的节点
// 这就是为什么在unparkSuccessor(Node)方法中要保证遍历是从后往前的,因为从后往前遍历是保证了准确性
node.prev = t;
// 入队操作,把当前的节点添加到队列的末尾中
if (compareAndSetTail(t, node)) {
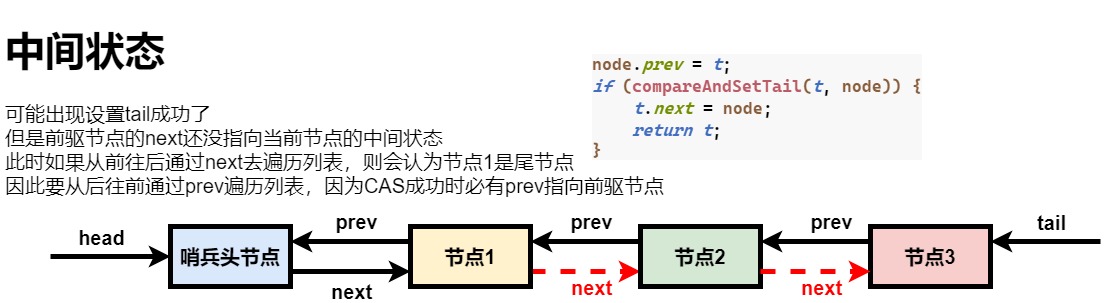
// 由于这里和compareAndSetTail不是原子的,因此有可能compareAndSetTail成功了,但是前置节点指针还未指向尾节点(即为空)的尴尬情况
// 也就是意味着,存在一种瞬时的状态,next节点指向空,但是此节点为非尾节点
// 因此next节点是不可靠的,因此unparkSuccessor(Node)需要从后往前遍历,因为prev节点是可靠的
t.next = node;
return t;
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
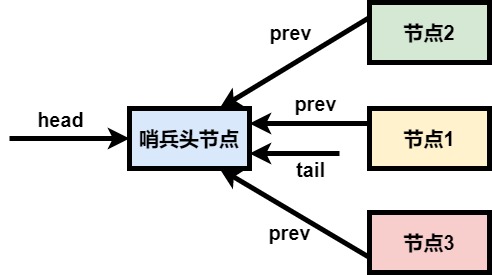
addWaiter先执行了快速入队处理,其实就是简单判断一下是否存在队尾节点,如果存在则进行快速入队
enq中,这个方法是做了完整的入队流程,其实按照本质上来说流程和上述的快速入队差不多
首先for循环保证了里面的入队逻辑是必须执行成功的
如果等待队列是空的,那么就要创建一个虚拟节点作为队头,注意不是把当前节点作为队头,而是新建的虚拟节点是队头;新建对头后,由于还在for循环中,那么会再次执行完整的逻辑入队处理
如果存在了等待队列,则执行以下三个动作,注意这三个动作不是原子性的
- 先把当前节点的前驱节点指向之前的队尾
- 进行CAS操作,把当前节点设置为队尾
- 把之前队尾的next节点指向当前节点
由于这3条执行指令的顺序性,那么能够说明下面两个重要点:
- 在执行compareAndSetTail成功后,一定能够保证当前节点的前驱指针已经指向原来的队尾节点
- 在compareAndSetTail成功后,t.next = node执行前,可能存在一种中间状态:tail指针已经指向当前的节点,但是原来的队尾节点的next指针还未指向当前的节点
因此,如果需要遍历这个虚拟队列,最好从后往前遍历,因为队列中的prev指针是可靠的,而next指针是不可靠的
/**
* 进行同步等待处理
* 1. 如果获取到执行权,那么线程继续执行
* 2. 否则进入等待队列中,并且等待其先驱线程的唤醒
*
* @param node 新的节点
* @param arg 获取的参数
* @return 线程在等待时,是否有被中断
*/
final boolean acquireQueued(final Node node, int arg) {
// 执行是否失败
boolean failed = true;
try {
// 线程是否被中断过
boolean interrupted = false;
for (; ; ) {
// 获取当前节点的前驱节点
final Node p = node.predecessor();
// 如果前驱节点是头节点,并且尝试获取到执行权
// 这里为什么还要判断一次tryAcquire呢?
// 是因为,第一个获得执行权的线程是可以不用进入等待队列的
// 因此这种情况还需要尝试获取一下执行权的
if (p == head && tryAcquire(arg)) {
// 把当前的节点设置成队列的头,此时线程已经获得了执行权
// 是一定能够保证线程安全的
setHead(node);
// 因为前驱节点已经失去了作用,最好把前驱节点设置为游离状态
// 这里帮助更快地进行GC操作
p.next = null;
failed = false;
return interrupted;
}
// 如果前驱节点不是头或者没有获取到执行权,那么线程就需要被挂起了
// 这里是线程的 RUNNABLE -> BLOCKED 状态的入口,也是 BLOCKED -> RUNNABLE的出口
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
// 在这里的清理动作其实意义不大
// 其实我认为执行到这里,最有可能的情况是tryAcquire报错了
// 因为tryAcquire是由用户进行实现的,因此可能报出一些运行时异常也是可能的
cancelAcquire(node);
}
}
/**
* 判断是否满足线程被挂起的条件
* 这里的代码是会修改CLH队列的
* <p>
* 1. 查询前驱节点的状态,若为SIGNAL返回true
* 2. 否则:
* 2.1 若当前节点的前驱节点为CANCELLED,则找出第一个不为CANCELLED的节点作为当前节点的前驱节点
* 2.2 若当前节点的前驱节点不为CANCELLED,则设置前驱节点的状态为SIGNAL
* 并且返回false
*
* @param pred 前驱节点
* @param node 需要判断的节点
* @return 当前线程是否需要被阻塞挂起
*/
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 获取并且判断前驱节点的状态
int ws = pred.waitStatus;
// 前驱节点为SIGNAL
if (ws == Node.SIGNAL)
return true;
// 如果前驱节点为CANCELLED
if (ws > 0) {
// 目标是找到一个不为CANCELLED的前驱节点,并作为当前节点的前驱节点
do {
// 此时跳过前驱节点
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
// 执行到这里就要退出返回此方法了
// 为什么这里不返回true呢
// 是因为本方法是cas执行的,意思是外层有for循环,再次执行会执行else中的代码片段
} else {
// 如果前驱节点不为CANCELLED
// 那么把前驱节点的状态设置为SIGNAL
// 这里尽管会出现竞争,但是总有一个线程会进行修改成功的
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
// 外层有for循环,再次执行会执行ws == Node.SIGNAL并且返回true
}
return false;
}
/**
* 挂起现在的线程,特点为:
* 1. park是不会抛出中断异常的
* 2. park是会相应对应的中断标记位的
* 3. Thread.interrupted()这个方法是查找中断标记位并清除对应的中断状态
* 4. 如果线程被挂起了,那么获得执行权时候会在park的下一句继续执行
*
* @return 线程是否有被中断
*/
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
- acquireQueued:进入同步等待队列,其中主要逻辑主体为一个大自旋操作,自选逻辑为:
- 判断当前节点的前驱节点是否为头节点,如果是,则尝试获取执行权,如果成功,则把队列头节点改为本节点,否则执行shouldParkAfterFailedAcquire
- 为什么还需要执行tryAcquire方法获取执行权呢?
- 是因为第一个进入的线程,是不用进入等待队列的,此时有可能出现一种情况,即第一个线程已经释放了资源,但是判断队尾没有等待队列,因此不做唤醒处理;后面又进来一个需要执行的线程,如果此时没有再进行tryAcquire,那么这个新线程是没办法执行的
- shouldParkAfterFailedAcquire做了一些判断修改的动作,保证在挂起前前驱节点处于SIGNAL状态
- parkAndCheckInterrupt,把当前的线程直接挂起,LockSupport.park(this)是线程运行状态->等待状态的转换点;当线程被unpark时,出口执行的第一个代码行为Thread.interrupted()
- 在执行park的时候,是不会抛出中断异常的,但是会响应中断标志位
- 在被unpark后,做的第一个事情是Thread.interrupted(),查询并清除对应的中断标记位
- 判断当前节点的前驱节点是否为头节点,如果是,则尝试获取执行权,如果成功,则把队列头节点改为本节点,否则执行shouldParkAfterFailedAcquire
# 释放执行权代码块
/**
* 释放资源
* 这里做的事情:
* 1. 释放占用资源(典型的就是操作state的值)
* 2. 把CLH队列头的下一个节点中保存的线程拿出来unpark
*
* @param arg 释放资源参数
* @return 资源是否完全被释放,注意不是本次释放成功!
*/
public final boolean release(int arg) {
// 尝试进行释放资源
if (tryRelease(arg)) {
// 获取头节点
Node h = head;
if (h != null && h.waitStatus != 0)
// 取消阻塞当前头节点的后继节点中的线程
unparkSuccessor(h);
return true;
}
return false;
}
/**
* 解锁后继线程,这里做了
* 1. 把当前节点的状态设置为0
* 2. 找出本节点的最近的非CANCELLED节点,并且释放它
*
* @param node 当前节点
*/
private void unparkSuccessor(Node node) {
int ws = node.waitStatus;
if (ws < 0)
// 把当前节点的状态设置为0,这里必定会有一个线程操作成功的,因此可以忽略返回值
compareAndSetWaitStatus(node, ws, 0);
Node s = node.next;
// 如果后继节点为空或者后继节点为取消状态
if (s == null || s.waitStatus > 0) {
s = null;
// 从后面往前面遍历节点,要求是:
// 1. 和当前的node节点不是同一节点
// 2. 当前的状态不是CANCELLED状态
// 这里出来的结果就是遍历出离node最近的一个可用节点
// 为什么要从后往前遍历呢?详情的原因看enq()的方法
// 如果从前往后遍历,会遇到一种情况是next指针为空而当前节点不是尾节点的情况
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
// unpark对应的线程
LockSupport.unpark(s.thread);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
- tryRelease,尝试释放执行权,简单而言就是对state状态的变更,由子类去覆盖
- unparkSuccessor具体唤醒在等待队列中的线程,在遍历时为什么要从后往前遍历呢?上文说过了prev指针是可靠的,在把一个节点设置成队尾前一定保证了prev节点指向原有的队尾,而next节点是不可靠的
# Lock和Synchronized区别
共同点:
- 协调资源临界区;
- 都是重入锁,同一个线程可以多次获取同一个锁;
- 保证了可见性和互斥性;
不同点:
- lock可以在申请锁时候限时等待,但synchronized不行;
- lock可以实现公平锁,但synchronized是非公平的;
- lock可以响应线程中断,但synchronized不行;
- lock是一个接口,synchronized是关键字,synchronized的实现原理是通过底层虚拟机以及内核实现的;
- synchronized会自动释放锁,lock手动释放;
- synchronized能锁住类、方法和代码块,但是lock只能锁范围代码块的;
- synchronized本质上调用底层mutex执行操作,需要使用monitorenter和monitorexit对代码块进行加锁,而lock是使用AQS实现的(AbstractQueuedSynchronizer)。
# 互斥锁和自旋锁
自旋锁:自旋锁在执行单元在获取锁之前,如果发现有其他执行单元正在占用锁,则会不停的循环判断锁状态,直到锁被释放,期间并不会阻塞自己。所以自旋锁使用时,是非常消耗CPU资源的。
互斥锁:会把自己阻塞并放入到队列中。当锁被释放时,会唤醒队列上执行单元把其放入就绪队列中,并由调度算法进行调度并执行。所以互斥锁使用时会有线程的上下文切换,这可能是非常耗时的一个操作,但是等待锁期间不会浪费CPU资源。
- 如果是多核CPU,上下文切换的时间开销比预计获取锁的等待时间要短,使用互斥锁更好;
- 如果是多核CPU,上下文切换的时间开销比预计获取锁的等待时间要长,使用自旋锁更好;
- 如果是单核CPU,使用互斥锁。
# CAS和对应的问题
CAS操作需要3个变量:
- 需要读写的内存位置V
- 预期值A
- 新值B
CAS操作时,需要判断V位置的值与预期值A是否相等,如果不相等,则不更改V位置的值,后续进行重新读取,重新进行计算操作;如果相等,则把该位置的值改变为B。
有以下缺点:
- ABA问题:有一个栈,其结构为A->B,线程1从堆顶读取A,希望将堆顶替换为B,此时线程2介入,线程2也从表头读取到A,将A和B出栈,将D、C、A分别入栈,成为A->C->D这种结构,而B则是游离状态;而此时线程1执行CAS操作,发现堆顶仍然是A,则把B改为堆顶,此时会导致把C和D元素丢弃了;解决方案:使用AtomicStampedReference(带时间戳)或者AtomicMarkableReference(单纯带状态)进行处理;
- 循环时间开销大:如果自旋CAS长时间不成功,会给CPU带来非常大的开销;
- 只能保证一个共享的原子变量:当只有一个共享变量时,可以使用CAS进行原子操作,但对于多个变量操作时,循环CAS无法保证操作的原子性。
# 锁优化
自旋锁与自适应自旋:
自旋锁:在JDK1.4时候引入,默认为关闭状态,JDK1.6时候默认开启。在获取锁的时候自旋,避免了线程切换之间的开销。缺点是如果锁被占用的时间很长,锁的自旋会白白浪费处理器资源。因此自旋锁有自旋次数的限制,默认为10次。
自适应自旋:自旋的次数和时间不再固定,由前一次在同一个锁上的自旋时间以及锁的拥有者状态决定。如果在同一个对象,自旋等待刚刚成功获得过锁,虚拟机认为本次自旋很有可能再次成功,允许自旋等待更长时间。如果自旋很少成功获得,以后则可能减少自旋时间或者略过自旋。
锁消除:
对一些代码上要求同步,但被检测到不可能存在共享数据竞争的锁进行消除。
锁粗化:
对同一个对象反复加锁,甚至加锁操作在循环体中出现,会频繁互斥同步导致性能损耗。因此可以使锁的范围粗化,减少反复加锁的次数。
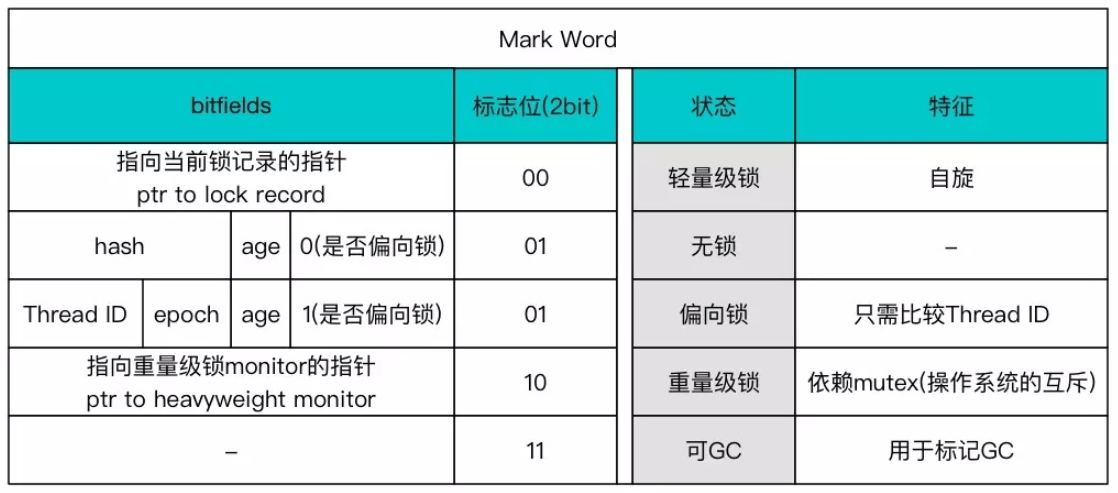
重量级锁和轻量级锁:
重量级锁:指的是传统意义上执行synchronized同步代码块时,加入字节码monitorenter和monitorexit指令来实现monitor的获取和释放,就是需要JVM通过字节码显式地去获取和释放monitor实现同步;使用synchronized同步方法时候,检查方法的ACC_SYNCHRONIZED标志是否被设置,如果设置了线程需要先去获取monitor。
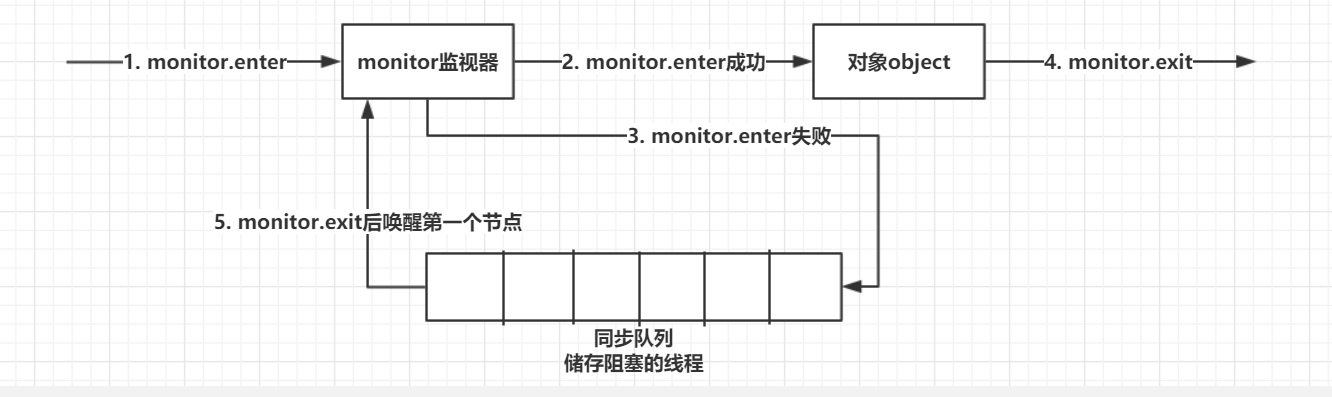
轻量级锁:为了在没有多线程竞争的前提下,减少传统重量级锁使用操作系统互斥量产生的性能消耗。在进入同步块时,虚拟机首先在当前线程栈帧中建立一个Lock Record空间,用于存储锁对象目前的Mark Word拷贝(官方把这份拷贝加了一个Displaced前缀,即Displaced Mark Word),并尝试使用CAS操作将锁对象的Mark Word更新为指向Lock Record的指针。如果更新成功,则当前线程拥有了对象的锁,并且将对象Mark Word的锁标志位改为00(轻量级锁)状态。如果更新失败了,检查锁对象Mark Word是否指向当前线程的栈帧,若是则说明已经拥有锁,同步代码块继续执行,若否则说明被抢占了。如果有两条以上的线程争用同一个锁,轻量级锁久不再有效,膨胀为重量级锁。
偏向锁:
总结:
| 锁类型 | 面向的场景 | 优点 |
|---|---|---|
| 偏向锁 | 只有一个线程进入临界区 | 加锁解锁速度非常快,和执行非同步方法仅存在纳秒级的差距 |
| 轻量级锁 | 多个线程交替地进入临界区 | 竞争的线程不会阻塞,提高了程序的响应速度 |
| 重量级锁 | 多个线程同时进入临界区 | 线程进行挂起,不会消耗CPU |
# 死锁
# 死锁出现的条件
- 互斥:对要求所分配的资源有排他性,即一段时间内某资源仅为一个进程所占有;
- 不可剥夺:进程所获得的资源未使用完之前,不能被其他进程强行夺走,只能由获得该资源进程自己释放;
- 请求与保持:进程已经保持了至少一个资源,但同时又提出了新的资源请求,而该资源已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放;
- 循环等待:多个进程之间形成一种头尾相接的循环等待资源关系。
# 如何处理死锁
- 预防死锁:破环上述四个条件的一个即可;
- 避免死锁:保证加锁的顺序,添加加锁的时限
- 死锁检测:允许系统中发生死锁,但可设置对应的死锁检测机制
- 解除死锁:当检测到死锁后,采取适当措施将进程从死锁状态解脱出来
# ThreadLocal
- 在高并发时可以使用ThreadLocal为每个线程单独分配一个对象,把共享对象拆分到具体一个线程一个,以空间换取时间的做法;
- ThreadLocal可能导致内存泄漏,Thread中有一个类型为ThreadLocal.ThreadLocalMap成员变量threadLocals,而ThreadLocal.ThreadLocalMap内部是使用Entry结构类型存储数据的,Entry本质上继承了WeakReference类,在发生GC时候,若ThreadLocal没有被外部强引用,则会被回收,若使用了ThreadLocal进行set的线程一直运行(典型情况下在线程池中运行),那么这个Entry对象的key值变为null,导致value值可能一直不能回收,从而发生内存泄漏;使用ThreadLocal类的set方法后,显式调用remove方法可以有效规避内存泄漏的问题;
- 参考文章:面试官:小伙子,听说你看过ThreadLocal源码?(万字图文深度解析ThreadLocal) (opens new window)
public class Thread implements Runnable {
//成员变量
ThreadLocal.ThreadLocalMap threadLocals = null;
}
2
3
4
5
6
public class ThreadLocal<T> {
static class ThreadLocalMap {
//与HashMap中的结构与想法类似
private Entry[] table;
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
private void set(ThreadLocal<?> key, Object value) {}
private void remove(ThreadLocal<?> key) {}
}
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# 拷贝/克隆
- 克隆类需要重写Object的clone()方法(显式提升clone的可见性);
- 克隆类需要实现java.lang.Clonable接口,如果没有实现改接口则会报出java.lang.CloneNotSupportedException异常;
- 如果克隆类中含有非基本数据类型,需要注意区分浅拷贝与深拷贝的问题。
浅拷贝&深拷贝:
在拷贝的过程中如果类中的属性不是基本数据类型,则拷贝后该属性指向原来被拷贝对象的属性,因此该属性的变动会间接影响另一个对象。
浅拷贝例子:
public class Person implements Cloneable {
private Integer age;
private String name;
private Address address;
@Override
protected Person clone() throws CloneNotSupportedException {
Person other = (Person) super.clone();
return other;
}
}
public class Address {
private String name;
private String type;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
执行:
public class TestClone {
public static void main(String[] args) throws CloneNotSupportedException {
Address address = new Address("广州", "home");
Person p1 = new Person(26, "jm", address);
Person p2 = p1.clone();
System.out.println(p1);
System.out.println(p2);
p2.getAddress().setType("office");
System.out.println(p1);
System.out.println(p2);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
输出为:
Person{age=26, name='jm', address=Address{name='广州', type='home'}}
Person{age=26, name='jm', address=Address{name='广州', type='home'}}
Person{age=26, name='jm', address=Address{name='广州', type='office'}}
Person{age=26, name='jm', address=Address{name='广州', type='office'}}
2
3
4
深拷贝,上面的代码改为:
public class Person implements Cloneable {
private Integer age;
private String name;
private Address address;
@Override
protected Person clone() throws CloneNotSupportedException {
Person other = (Person) super.clone();
Address otherAddress = getAddress() == null ? null : getAddress().clone();
other.setAddress(otherAddress);
return other;
}
}
public class Address implements Cloneable {
private String name;
private String type;
@Override
protected Address clone() throws CloneNotSupportedException {
return (Address) super.clone();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
输出为:
Person{age=26, name='jm', address=Address{name='广州', type='home'}}
Person{age=26, name='jm', address=Address{name='广州', type='home'}}
Person{age=26, name='jm', address=Address{name='广州', type='home'}}
Person{age=26, name='jm', address=Address{name='广州', type='office'}}
2
3
4
# 代理
# 静态代理
对于特定的类或者接口的某些方法进行无入侵式的扩充,可以不修改代理对象的前提下扩展被代理对象的功能,但被代理的范围仅限于某一种类的对象。
public interface IPerson {
String say();
}
public class Student implements IPerson {
private String name;
public Student() {
}
public Student(String name) {
this.name = name;
}
@Override
public String say() {
System.out.println("我是:" + this.name);
return this.name;
}
}
public class PersonProxy implements IPerson {
private IPerson target;
public PersonProxy(IPerson target) {
this.target = target;
}
public PersonProxy() {
}
@Override
public String say() {
System.out.println("我准备发言了");
String say = this.target.say();
System.out.println("我发言完毕了");
return say;
}
public static void main(String[] args) {
Student student = new Student("jm");
IPerson personProxy = new PersonProxy(student);
personProxy.say();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
输出:
我准备发言了
我是:jm
我发言完毕了
2
3
# 动态代理
- 动态代理是运行时动态生成的,编译完之后不生成字节码文件,而是运行时动态生成字节码文件并且自动加载到Jvm中使用的;
- 如果有多个被代理类的增强实现都是一样的,例如:打印RPC调用的入参参数,其中由于RPC可以有多种调用方式(TCP、HTTP等),使用静态代理就需要创建很多代理类,略显繁琐,因此使用动态代理,可以把具体的增强业务逻辑放在InvocationHandler中,把产生的代理对象的逻辑放在Proxy中。
# JDK代理
JDK动态代理的对象无需实现被代理的接口,但是要求目标代理对象必须实现接口。
使用的类有:
- java.lang.reflect.Proxy类:生成具体代理对象的类。
public static Object newProxyInstance(ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h)
2
3
- java.lang.reflect.InvocationHandler:需要实现此接口,其中在invoke方法中需要对被代理对象执行发放的具体拦截分发。
public Object invoke(Object proxy, Method method, Object[] args)
代码样例:
public class PersonProxy implements IPerson {
private IPerson target;
public PersonProxy(IPerson target) {
this.target = target;
}
public PersonProxy() {
}
@Override
public String say() {
System.out.println("我准备发言了");
String say = this.target.say();
System.out.println("我发言完毕了");
return say;
}
@Override
public void eat() {
System.out.println("我正在吃饭");
}
public static void main(String[] args) {
Student student = new Student("jm");
IPerson personProxy = new PersonProxy(student);
personProxy.say();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# CGLIB代理
- 使用CGLIB可以代理无接口的类;
- 本质上使用ASM工具,在ASM加载类之前,动态改变类的行为;
- 比原生的JDK代理更加灵活,被代理类无需实现接口。
# 细节
# Map之间多个实现类以及衍生类的异同
HashMap重点:
- 实现方式:1.8后使用数组+链表+红黑树的方式实现,1.8前使用数组+链表实现;初始化容量capacity=(1<<4)=16,负载因子factor=0.75f,红黑树化阈值=8,红黑树退化阈值=6,最小红黑树容量=64,在map初始化时,对应的数组仍未初始化。1.8以前使用头插法对元素进行插入,插入的元素在链表的表头位置,原因时作者认为最新插入的元素查询的价值最高,因此更容易访问到,但头插法容易在hashmap进行并发使用resize时出现循环链表的现象。1.8后使用了尾插法,因为尾插法本质上不改变原有头部指针的指向,因此不会出现循环链表的现象。
- get操作:先对key进行hash操作,然后取出HashMap中数组长度 - 1 & 对应计算出来的哈希值,原因是:HashMap数组的长度必须为2的幂次,因此对应-1的二进制数值全为1,&上哈希值后其实就是取对应哈希值的后几位,此时比求余运算速度快得多,取出对应链表头节点后,如果是红黑树,则对应使用红黑树的遍历方式获取值(时间复杂度为O(logn)),如果是链表则使用遍历方式获取(时间复杂度为O(n))。
- put操作:如果当前数组为空或者数组长度为0,则先对map进行resize处理。获取对应key的表头位置,生成对应node节点,遍历链表,如果找到对应替换位置则进行元素替换,如果到达链表末尾,则需要判断是否需要对链表进行红黑树化,最后进行resize操作。
- resize操作:每次resize都会把数组大小变成原来的2倍。重新计算元素下标位置时,元素要么保持在原来的下标位置,要么移动到原位置+旧数组长度位置。如果元素hash值&旧数组长度大小为0,则保持原来位置,如果不为0则移动到2次幂位置,这是因为数组变成原来的2倍,可以理解为元素计算的下标比原来多1位,要么保持位置不变,要么移动到新的位置上。1.8后对resize进行优化,优化后resize不会改变链表元素的顺序。
HashMap和Hashtable的区别:
- HashMap非线程安全的,而Hashtable是线程安全的;
- HashMap的的key和value都可以为空,而Hashtable都不能为空;
- 计算数组index的流程不一样,HashMap为hash & (table.length-1),Hashtable为(e.hash & 0x7FFFFFFF) % newCapacity;
- 扩容不一样,HashMap扩容为原来的2倍,Hashtable扩容为2倍+1。
HashMap、LinkedHashMap、TreeMap的关系:
- LinkedHashMap是HashMap的子类;
- LinkedHashMap维护一个双向链表,可以保证迭代的顺寻按照put的顺序;
- TreeMap维护一个红黑树,迭代时按照自然排序或者自定义排序(常用入参为Comparator);
- HashMap和LinkedHashMap需要元素重写equals和hashcode方法,而TreeMap本质上是一个SortedMap,需要元素实现Comparable接口。
# List之间多个实现类以及衍生类的异同
ArrayList、LinkedList、Vector、CopyOnWriteArrayList区别以及关系:
- ArrayList基于数组实现,需要动态扩容(每次扩容到原来的1.5倍),根据index查找速度为O(1),基于非后最元素的add或者delete速度很慢,适合固定大小以及常用遍历的场景;继承RandomAccess快速随机访问接口,用for循环迭代比使用iterator快;
- LinkedList基于链表实现,无须动态扩容,根据index遍历比较慢,但是add或者delete速度较快,适合查少改多的场景;
- Vector线程安全,但已经弃用,Vector可以使用Enumeration和Iterator进行元素遍历,ArrayList只提供了Iterator的方式;
- CopyOnWriteArrayList线程安全,是牺牲内存空间的前提下,保证了数据的最终一致性。在CopyOnWriteArrayList进行增删改时,先进行加锁,然后把原数组拷贝到一个副本内,拷贝完成时把原数组指向副本数组,再解锁。在读取时,直接遍历内部的数组即可,保证了最终一致性。而Vector在进行for循环遍历时,使用vector.size()获取长度遍历,仍然存在其他线程修改vector.size()属性,导致vector遍历出现ArrayIndexOutOfBoundsException。
# ArrayList删除元素
- 使用迭代器删除(iterator)
- 赋值给新的list
- 从后面的元素开始反向删除
- 正序删除后修正下标值
- 使用removeIf方法
- 使用stream的filter进行元素过滤
# fail-fast机制和fail-safe机制
- fail-fast(快速失败):利用迭代器遍历集合时候,如果遍历过程中对内容进行修改,则会抛出ConcurrentModificationException。在遍历集合中的元素时,记录modCount变量,如果集合发生变化,就会修改modCount的值。遍历过程中(过程后)判断当前的modCount和遍历前modCount是否相等,如果是就返回遍历结果,否则抛出异常终止遍历;在java.util包下所有集合都是快速失败的,不能再多线程下并发修改。
- fail-safe(安全失败):在遍历时复制原有集合内容,在拷贝的集合上进行遍历。在遍历期间集合发生修改,迭代器是无法感知的。在java.util.concurrent包下容器都是安全失败的。
| Fail Fast | Fail Safe | |
|---|---|---|
| 抛出ConcurrentModificationException | 是 | 否 |
| 拷贝元素 | 否 | 是 |
| 是否会导致内存溢出 | 否 | 是 |
| 遍历时修改元素是否能被感知 | 是(抛出异常) | 否 |
| 用例 | HashMap,Vector,ArrayList,HashSet | CopyOnWriteArrayList,ConcurrentHashMap |
# 几个队列常用的API
# Stack
| 操作 | 描述 |
|---|---|
| E peek() | 弹出栈顶元素,但是不移除 |
| E pop() | 弹出栈顶元素,移除元素 |
| E push(E e) | 压入元素到栈顶 |
# Queue
| 操作 | 异常 | 操作描述 |
|---|---|---|
| boolean add(E e); | 是 | 添加一个元素到队尾,如果队列已满则抛出IllegalStateException |
| boolean offer(E e); | 否 | 添加一个元素到队尾,并返回添加是否成功 |
| E remove(); | 是 | 取出队列中的头元素,如果队列为空则抛出NoSuchElementException |
| E poll(); | 否 | 取出队列中的头元素,如果队列为空则返回null |
| E element(); | 是 | 获取队列中的头元素,如果队列为空则抛出NoSuchElementException |
| E peek(); | 否 | 获取队列中的头元素,如果队列为空则返回null |
上述的方法均不阻塞,下面两个方法是摘自BlockingQueue的,下面两个方法均阻塞,因为是同步等待的,因此是不会抛出对应的异常的
| 操作 | 异常 | 操作描述 |
|---|---|---|
| void put(E e); | 否 | 添加一个元素,如果队列为满则一直阻塞 |
| E take(); | 否 | 取出队列中的头元素,如果队列为空则一直阻塞 |
# Deque
| 操作 | 异常 | 操作描述 |
|---|---|---|
| boolean addFirst(E e); | 是 | 添加一个元素到队头,如果队列已满则抛出IllegalStateException |
| boolean offerFirst(E e); | 否 | 添加一个元素到队头,并返回添加是否成功 |
| boolean addLast(E e); | 是 | 添加一个元素到队尾,如果队列已满则抛出IllegalStateException |
| boolean offerFirst(E e); | 否 | 添加一个元素到队尾,并返回添加是否成功 |
| E removeFisrt(); | 是 | 取出队列中的头元素,如果队列为空则抛出NoSuchElementException |
| E pollFirst(); | 否 | 取出队列中的头元素,如果队列为空则返回null |
| E removeLast(); | 是 | 取出队列中的尾元素,如果队列为空则抛出NoSuchElementException |
| E pollLast(); | 否 | 取出队列中的尾元素,如果队列为空则返回null |
| E elementFirst(); | 是 | 获取队列中的头元素,如果队列为空则抛出NoSuchElementException |
| E peekFirst(); | 否 | 获取队列中的头元素,如果队列为空则返回null |
| E elementLast(); | 是 | 获取队列中的头元素,如果队列为空则抛出NoSuchElementException |
| E peekLast(); | 否 | 获取队列中的头元素,如果队列为空则返回null |
# SPI
SPI全称为Service Provider Interface,通过本地方式加载第三方扩展的方式启用框架或代码实现的组件;
常用在以下场景:
- JDBC4后数据库驱动加载接口的实现
- 日志门面接口实现类加载
- Spring:对servlet3.0规范的实现,自动类型转换
在com.spi包下,新建几个类:
public interface Animal {
String shout();
}
public class Cat implements Animal {
@Override
public String shout() {
return "喵";
}
}
public class Dog implements Animal {
@Override
public String shout() {
return "汪";
}
}
public class Test {
public static void main(String[] args) {
ServiceLoader<Animal> animals = ServiceLoader.load(Animal.class);
for (Animal animal : animals) {
System.out.println(animal.shout());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
在resources文件夹下,新建META-INF\services\com.api.Animal文件,文件内容为:
com.api.Cat
com.api.Dog
2
# 分布式事务
# 基础理论
CAP定理:任何一个系统都只能满足CAP中的任意两个方面
C:consistency,一致性,A:Avaliability,可用性,P:Partition Tolerance,分区容错性
BASE理论:保证核心功能可用,允许系统中存在中间状态,最终一致
BA:Basically avaliable,基本可用,S:Soft state,软状态,E:Eventually consistent,最终一致性
# 实现方式
# 2PC
两个角色:协调者和调用者;
两个阶段:询问和提交回滚阶段;
需要实现:XA协议,包括Prepare、Commit和Rollback接口;
缺点:
- 在询问阶段锁定资源,如果有一个参与者超时,则会同步阻塞所有微服务;
- 对协调者的依赖很严重,如果协调者单点故障,则无法正常工作;
- 会出现脑裂的情况,有些参与者收到并执行了事务,有些没有收到事务就没有执行。
# TCC
Try、Confirm和Cancel单词的缩写,也是简化版的3段提交协议(把询问阶段和准备阶段合并在一起),本质上是把一个事务拆分成两个事务进行操作,也需要业务进行改造支持处理
第一阶段:负责检查和锁定资源,需要做预操作处理,增加业务的“中间状态”;
第二阶段:无需进行资源检查,把业务的“中间状态”转为最终状态,若事务失败,则调用回滚操作,把第一阶段的锁定资源释放掉(做一次数据库的反操作),如果第二阶段失败了,则不断重试。
缺点:
- 业务入侵性强,改造成本高;
- 需要实现Confirm和Cancel接口的幂等性,因为第二阶段可能存在不断重试的情况;
# 本地事务表+消息队列
发送方增加一张消息表和一个轮询查表的线程,发送方不直接发送到消息队列,而是把具体业务和写消息表放在同一个事务中。轮询查表线程不断轮询,不断地捞取消息并把消息传给消息队列,经过消息队列ACK机制说明发送成功,没有经过ACK,则说明失败需要重传。服务提供方需要增加判重表,记录成功处理消息ID和消息中间件对应的offset(保证消息幂等),提供方宕机后定位到offset位置继续进行消费。
缺点:
- 需要在接收方保证消息的幂等,因为有可能重复消费;
- 需要在发送方增加无用的消息表和后台线程;
- 增加了业务的耦合度。
# RocketMQ事务消息
- 消费方调用RocketMQ的prepare接口,预发送消息。此时消息保存在消息中间件里,但消息中间件不会把消息发送给消费方;
- 消费方执行自己的业务逻辑(更新数据库);
- 消费方调用confirm接口,确认发送消息,此时消息中间件才会把消息推送给消费方进行消费;
当步骤2或3失败时,RocketMQ会回调给发送方,询问消息是要发送还是要取消。
# 统一登录流程
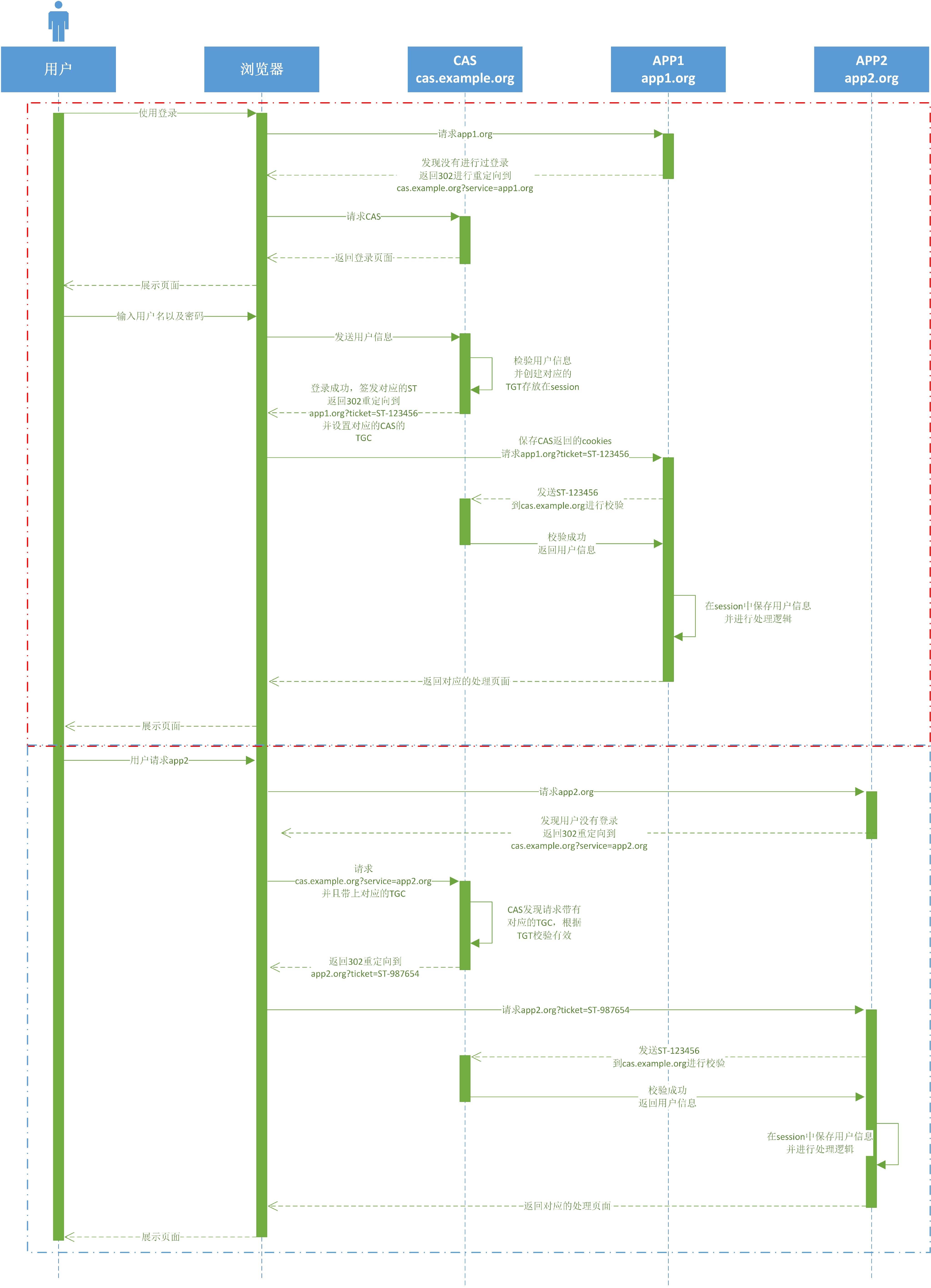
# CAS登录流程
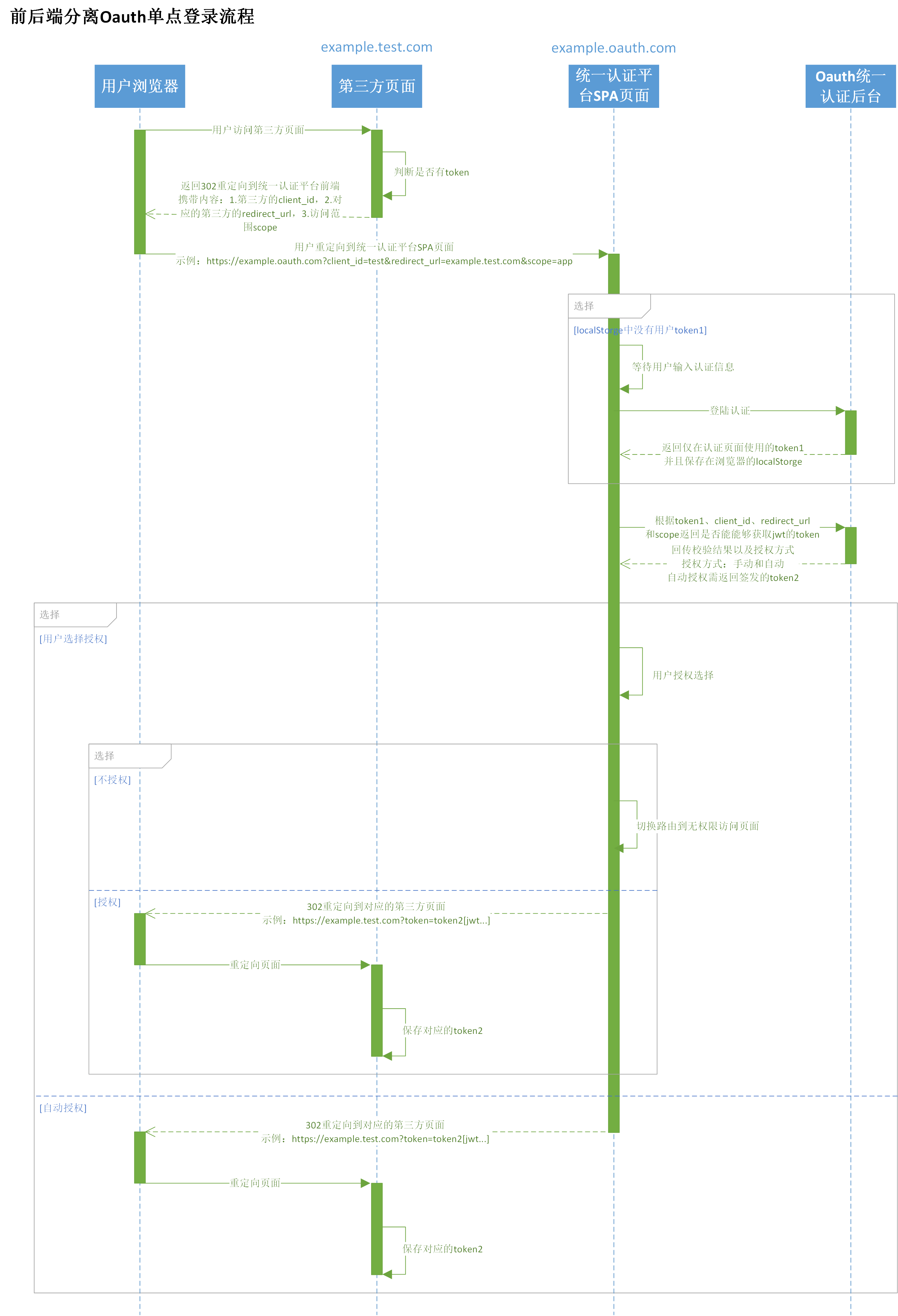
# Oauth登录流程
# 授权码模式

# 简化模式

# 密码模式

# 客户端模式

# 4种模式的区别
| 模式 | 场景 | 备注 |
|---|---|---|
| 授权码模式 | 不信任的第三方机构组织使用 | 非常安全但对接li联调的复杂度和成本很高,重要的流程是以code获取access_token的步骤(第三方后台自主获取token,不通过前端浏览器),签发access_token的同时可以签发fresh_token |
| 简化模式 | 公司系统内部子系统使用 | 本质上对接的流程都在前端浏览器完成,不可以签发fresh_token,在浏览器的local storage中保存对应的access_token |
| 密码模式 | 高度信任的机构或内部系统使用,前提是保存不保存用户信息 | 不安全,需要高度信任第三方机构组织,所以一般很少使用 |
| 客户端模式 | 不是以用户个人名义获取资源,而是以客户端自己的名义获取资源,开放权限的颗粒度比较高 | 需要授予第三方账号比较高的权限 |
# 隔离熔断限流降级
- 隔离:
- 数据隔离:把重要数据,冷热数据和不用业务的数据隔离;
- 机器隔离:按照服务调用者的重要程度以及性能等级排序;
- 线程池隔离:为RPC调用单独准备一个线程池,使调用接口不会饱和堆积;
- 限流:
- 使用Nginx的limit_conn、limit_req模块,或者Guava的RateLimiter模块;
- 秒杀系统中,有特定的库存数量,在Redis中为每一个库存设置对应的一个key,抢购时在Redis中消耗对应的key,然后进入消息队列进行异步的下单;
- 限流算法:包括漏桶和令牌桶算法。漏桶算法是指流出的速率是恒定的,若超过容量则溢出处理。而令牌桶则是以固定速率产生令牌,每一个请求需要取到令牌才能继续处理,若处理不到则丢弃请求。重要区别,令牌桶能够响应突发的情况,限制的是平均流入率而不是瞬时速率,因为可能一段时间没有请求进入,令牌桶塞满令牌,然后短时间内突发流量过来,一瞬间消耗多个令牌。而漏桶则是起到了流量削峰的作用;
- 熔断:根据请求的失败率和请求时间判断服务是否可用;
- 降级:保证系统核心功能仍然可用,而一些非核心非重要的功能可以以有损的方式提供服务。
# 如何做高可用
- 分布式架构,拆成多个模块或微服务,相互之间不影响,提高容错能力
- 集群多节点:将流量均匀分发到服务器上,避免单点故障
- 配置故障切换机制,及时拆掉故障节点,
# 缓存穿透、缓存击穿、缓存雪崩
# 缓存穿透
指用户访问缓存和数据库都没有的数据,导致负载都落在数据库中,导致压力过大
- 在接口维度增加参数校验,对参数进行合法性判断
- 若从数据库读取不到数据,也将null值设置到缓存中,并设置过期时间
- 使用布隆过滤器
# 缓存击穿
指缓存中原来有热点数据,但是热点的key突然失效了,导致大量的请求打到db
- 把热点key的时效性设置为永久
- 增加互斥锁,在第一个查询来的时候加上锁,把数据库数据缓存到缓存层后再释放锁,后续的服务都能访问到缓存
# 缓存雪崩
指缓存中大批量的数据到过期时间,查询数据巨大导致数据库压力过大
- 缓存数据过期时间预设随机值,防止同一时间大量数据过期现象发生
JVM →