
# 内存映射与零拷贝
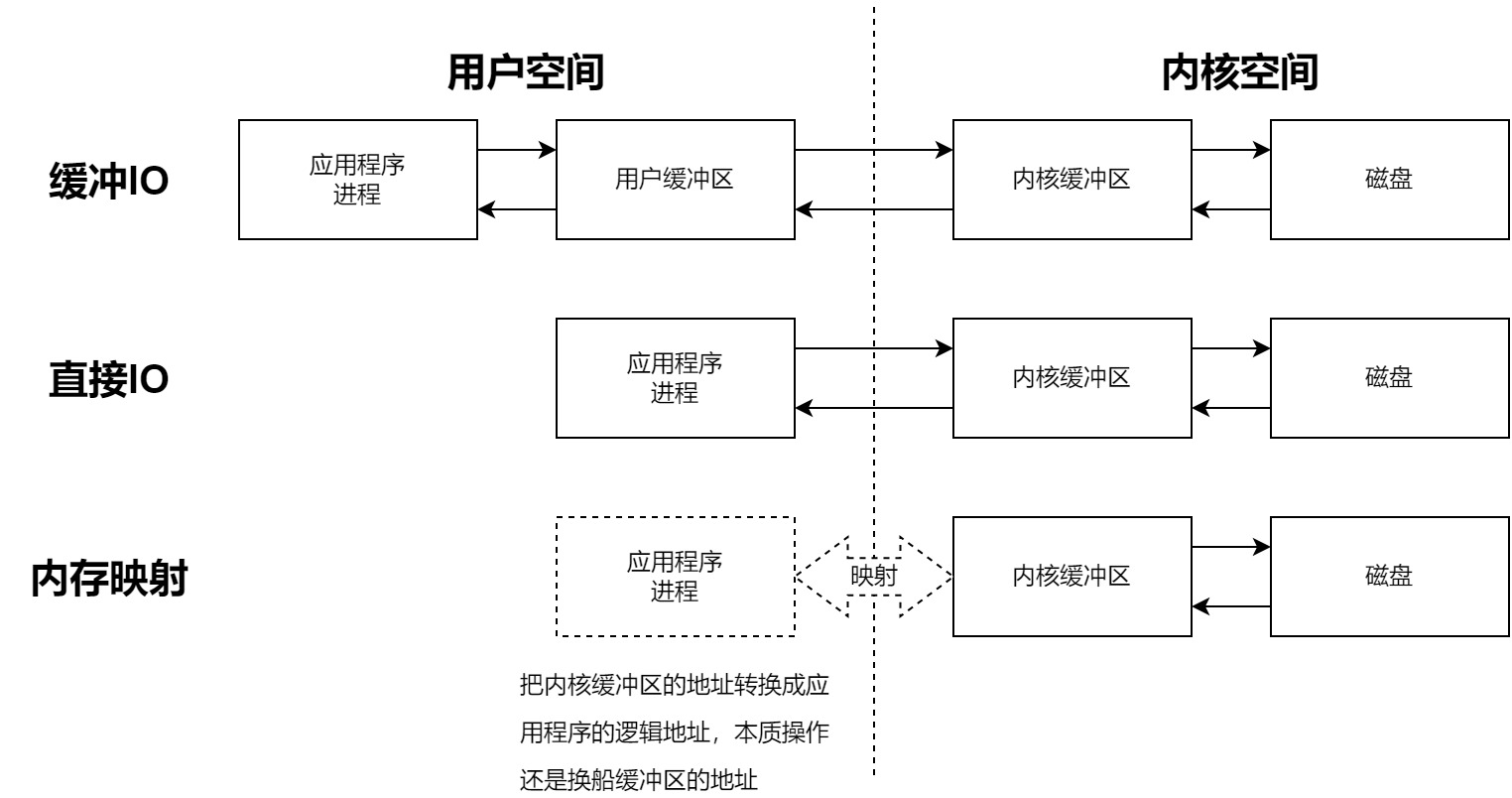
- 对于缓冲IO:有3次数据拷贝,应用程序<->用户缓冲区,用户缓冲区<->内核缓冲区,内核缓冲区<->磁盘
- 对于直接直接IO:有2次数据拷贝,应用程序<->内核缓冲区,内核缓冲区<->磁盘
- 对于内存映射:有1次数据拷贝,内核缓冲区<->磁盘,本质上应用程序和内核缓冲区共用一段内存地址,用同一份数据
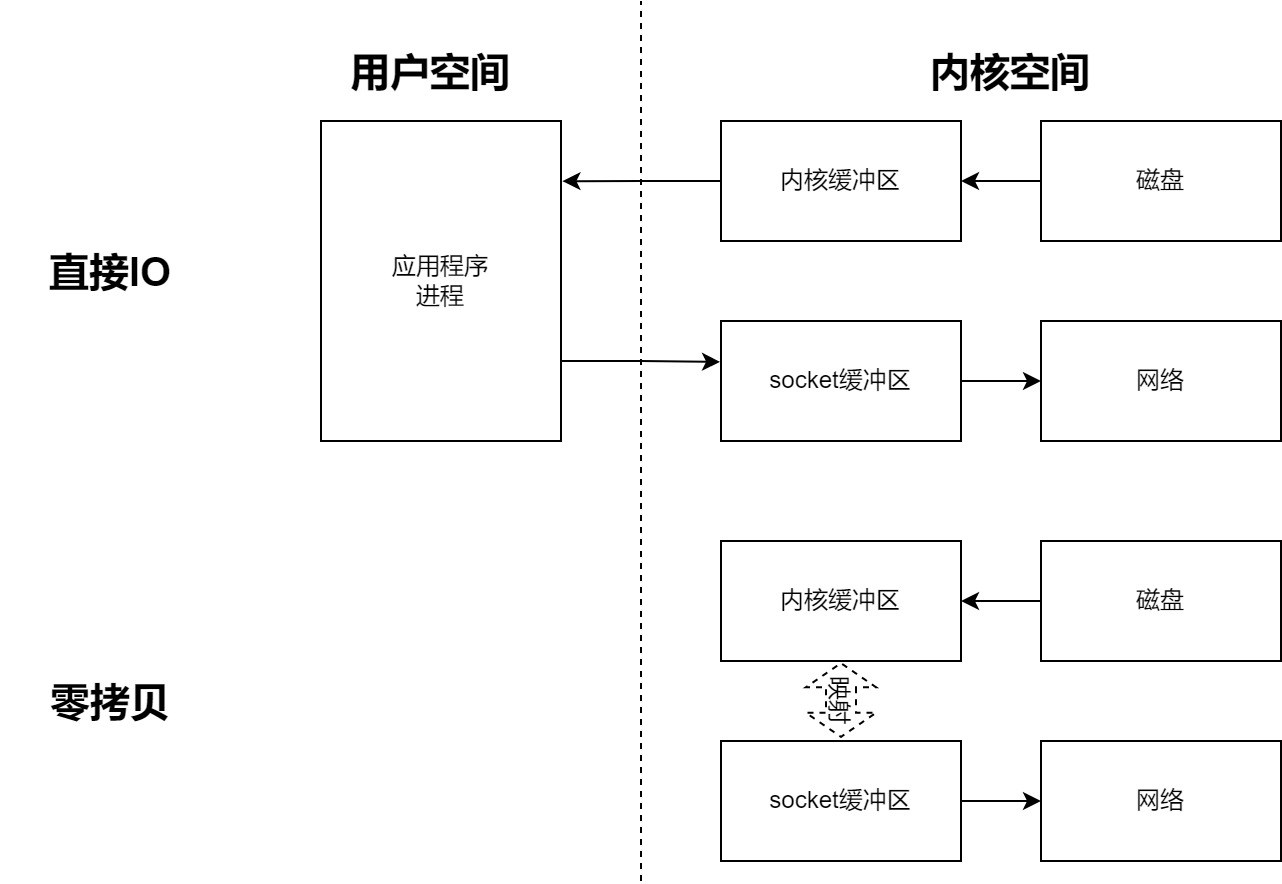
- 直接IO方式(传统方式):数据从磁盘发送到网络,有4次拷贝,磁盘->内核缓冲区->应用程序->socket缓冲区->网络
- 零拷贝:有2次拷贝,磁盘->内核缓冲区,socket缓冲区->网络,其中零拷贝是针对内存而言的,数据没有在内存里面发生过拷贝的动作
下面是一个零拷贝的demo例子:数据从test.log里面零拷贝到socket里面,打开程序,打开cmd并输入telnet 127.0.0.1 8888,会立即回显test.log里面的内容
public class ZerocopyTest {
public static void main(String[] args) throws IOException {
File file = new File("test.log");
RandomAccessFile raf = new RandomAccessFile(file, "r");
FileChannel channel = raf.getChannel();
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress(8888));
while (true) {
SocketChannel accept = serverSocketChannel.accept();
channel.transferTo(0, channel.size(), accept);
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# CPU密集型与IO密集型
| 类型 | 定义 |
|---|---|
| CPU密集型 | 也叫计算密集型,系统大部分时间状况是CPU占用率很高(有很多的计算任务需要完成),I/O在很短时间就可以完成。需要提高代码的运行效率,对于密集型的任务,最好使用C语言编写,而不要使用python |
| IO密集型 | 大部分状况是CPU等待I/O的读写操作,常见的大部分任务都是I/O密集型任务,比如web应用。使用运行速度块的语言无法很好地提升运行效率,因此比较适合开发效率高(代码量少,库类多)的语言进行编写 |
# 术语
- RTT:网络数据往返延时,为数据完全发送完(完成最后一个比特推送到数据链路上)到收到确认信号的时间
- 并发:多个任务交替地执行,但多个任务之间有可能还是串行的
- 并行:并行是多个任务同时执行
# IO模型
# 详解
IO的阻塞仅针对于操作系统可预见Block才会发生Block。
因此,对于磁盘文件IO,磁盘硬件的抖动导致IO发生阻塞不属于Block范畴,而从socket中read数据的过程则是属于Block范畴。
针对于多核CPU机器,Block仅阻塞当前进程。
一般多核CPU都是基于抢占式进行任务调度的,发生Block仅阻塞当前进程,而不会影响其他进程。
| 分类 | I/O模型 | 具体实现 | 详细描述 |
|---|---|---|---|
| 同步I/O | 同步阻塞I/O(BIO) | 阻塞式的read和write函数调用 | 当用户线程发出IO请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用 户线程交出CPU。当数据就绪之后,内核会将数据拷贝到用户线程,并返回结果给用户线程,用户线程才解除block状态。 |
| 同步I/O | 同步非阻塞I/O | 以O_NOBLOCK参数打开fd,然后执行read和write函数调用 | 当用户线程发起一个read操作后,并不需要等待,而是马上就得到了一个结果。如果结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。 |
| 同步I/O | I/O多路复用(同步阻塞)(NIO) | Linux系统下的三种I/O多路复用的实现方式:select、poll、epoll和Java中的NIO | 在多路复用IO模型中,会有一个线程不断去轮询多个socket的状态,只有当socket真正有读写事件时,才真正调用实际的IO读写操作。因为在多路复用IO模型中,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有在真正有socket读写事件进行时,才会使用IO资源,所以它大大减少了资源占用。 |
| 异步I/O | 异步I/O(AIO) | Windows上的IOCP,C++Boost asio库(框架模拟出来的异步I/O),Linux aio | 当用户线程发起read操作之后,立刻就 可以开始去做其它的事。而另一方面,从内核的角度,当它受到一个asynchronous read之后, 它会立刻返回,说明read请求已经成功发起了,因此不会对用户线程产生任何block。然后内核会等待数据准备完成,将数据拷贝到用户线程,当这一切都完成之后,内核会给用户线程发送一个信号,告诉它read操作完成了。也就说用户线程完全不需要实际的整个IO操作是如何进行的,只需要先发起一个请求,当接收内核返回的成功信号时表示IO操作已经完成,可以直接去使用数据了。 |
# Linux内核实现的多路复用的方法:
select:每次select时需要遍历整个FD集合,不管FD是否是活跃状态。如果没有发现就绪状态,则挂起当前的线程,直到就绪或者主动超时;
优点:
- 良好的跨平台支持。
缺点:
- 是单个进程所能监视的文件描述数量存在最大限制;
- 对socket进行扫描是线性的,采用轮询方式,效率低;
- 需要内核与用户空间中复制FD数组,开销大。
poll:与select没有本质区别,就是存放FD的集合数据结构不一样:基于链表进行数据存储的,因此没有FD的数量限制;
epoll:需要在linux内核2.6以上,当数据准备完成时内核主动触发回调。
两种工作模式:
- 水平触发(LT)(默认的工作方式):
- 读缓冲区非空,有数据可读,一直发出可读信号;
- 写缓冲区不满,有空间可写,一直发出可写信号;
- redis使用LT模式;
- 边缘触发(ET):
- 读缓冲区由空转为非空,发出一次可读信号;
- 写缓冲区由满转为不满,发出一次可写信号;
- nginx使用ET模式;
优点:
- 没有最大并发连接的限制;
- 不是轮询的方式进行查询,不会随着FD数量的增多导致效率下降:只要遍历那些被内核IO唤醒而加入ready队列的FD即可;
- 使用mmap方式进行消息传递,减小开销;
- 仅针对活跃的FD有效,非活跃的FD则不会进行回调。
- 水平触发(LT)(默认的工作方式):
# BIO、NIO、AIO的区别
BIO
- 等待数据处理完成之后再执行后续的业务内容,数据等待过程中无法做其他事情
- 占据单个线程(一定程度上占据单个CPU)
- 一般来说一次通信建立一个线程,连接数和线程数是1:1关系
NIO
- 不断轮询数据的可用性
- 轮询时间不好把控,过长则会程序延时过大,过短会导致CPU空转
- 连接线程数与后台处理线程数是N:1的关系
- NIO的一个实现:多路复用
- 通知内核程序需要监视某些FD是否有IO事件发生,IO多路复用和NIO需要配合一起使用才有实际意义
- IO多路复用和NIO是相对独立的两种事情,NIO是指IO不会发生阻塞,马上返回,而IO多路复用则是操作系统提供的一种简便的消息通知机制
AIO
- 将回调事件注册到内核中,等到数据准备完成(有效)时进行回调
- 类似于发布-订阅的数据通知方式
# 内存IO调用方式以及区别
- 缓冲IO:3次数据拷贝
- 读:磁盘->内核缓冲区->用户缓冲区->应用程序内存
- 写:应用程序内存->用户缓冲区->内核缓冲区->磁盘
- 直接IO:2次数据拷贝
- 读:磁盘->内核缓冲区->应用程序内存
- 写:应用程序内存->内核缓冲区->磁盘
- 内存映射:1次数据拷贝
- 读:磁盘->内核缓冲区--(映射)-->应用程序内存
- 写:应用程序内存--(映射)-->内核缓冲区->磁盘
- 零拷贝:0次数据拷贝
- 读:磁盘--(映射)-->内核缓冲区
- 写:内核缓冲区--(映射)-->磁盘
# Netty的代码样例
public class NettyServer {
public static void main(String[] args) throws InterruptedException {
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
ChannelPipeline pipeline = socketChannel.pipeline();
pipeline.addLast(new StringDecoder());
pipeline.addLast("encoder", new ObjectEncoder());
pipeline.addLast(" decoder", new ObjectDecoder(Integer.MAX_VALUE, ClassResolvers.cacheDisabled(null)));
pipeline.addLast(new NettyServerHandler());
}
})
.option(ChannelOption.SO_BACKLOG, 128)
.childOption(ChannelOption.SO_KEEPALIVE, true);
ChannelFuture f = b.bind(8000).sync();
System.out.println("服务端启动成功,端口号为:" + 8000);
f.channel().closeFuture().sync();
} finally {
workerGroup.shutdownGracefully();
bossGroup.shutdownGracefully();
}
}
}
public class NettyServerHandler extends ChannelInboundHandlerAdapter {
RequestHandler requestHandler = new RequestHandler();
@Override
public void handlerAdded(ChannelHandlerContext ctx) throws Exception {
Channel channel = ctx.channel();
System.out.println(String.format("客户端信息: %s", channel.remoteAddress()));
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
Channel channel = ctx.channel();
String request = (String) msg;
System.out.println(String.format("客户端发送的消息 %s : %s", channel.remoteAddress(), request));
String response = requestHandler.handle(request);
ctx.write(response);
ctx.flush();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# Netty解决TCP粘包的问题
粘包:是由于程序
# CPU(重点关注)
| CPU使用率 | CPU Load | |
|---|---|---|
| 定义 | 程序对CPU的时间片的占用情况 | 计算机系统执行计算任务数量的度量 |
| 含义 | 代表CPU在某个时间CPU的被占用情况 | 代表在单位时间内需要CPU去处理的任务数量 |
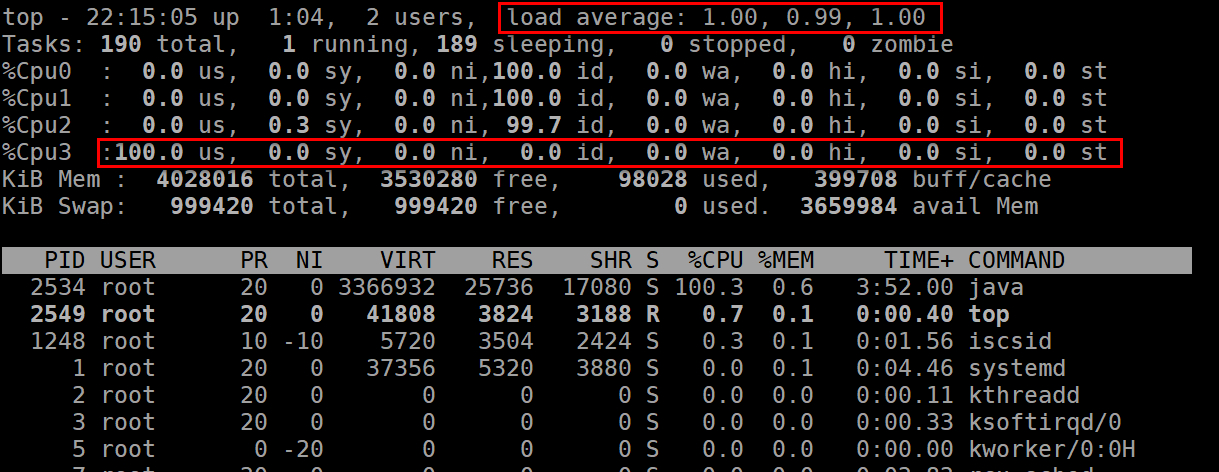
| 查看方法 | top命令,可以按1查看每个CPU的工作情况 | top命令,显示的load average后面的3个参数 |
| 各项性能指标参数的具体含义 | us,user:用户进程占用的CPU时间 sy,system:内核进程占用的CPU时间 ni,niced:运行已调整优先级用户进程占用CPU时间 id,idle time:空闲所占用CPU的时间 wa,IO wait:等待输入输出占用CPU的时间 hi,hardware interrupts:硬件中断占用CPU的时间 si,software interrupts:软件中断占用CPU的时间 st,steal time,被虚拟机占用的CPU的时间 | CPU在过去1分钟,5分钟,15分钟的平均Load |
| 备注 | 默认显示的是所有cpu加起来的一个值,所以可能超过100% | load average是基于内核数量决定的,简单理解为每个内核load之和,按照每个内核为1的负载来算,4个内核则对应的值为4,单个内核的性能指标最好不超过0.7 |
正常情况下,cpu率高,load也会比较高,但也有例外的情况,如:
- load低,利用率高:如果CPU执行的任务数量少,则load会低,但是任务都是CPU密集型的,利用率就会高
- load高,利用率低:如果CPU执行的任务数量多,则load会高,但是任务执行过程中CPU经常空闲(比如等待IO),利用率就会低
# TCP/IP协议相关
# 从输入URL到网页呈现,发生了什么事情
- 浏览器检查对应的缓存,如果有缓存且缓存仍可生效,跳转到9
- 浏览器访问系统对应域名的地址
- 系统首先检查本机内是否有缓存到对应的域名和IP地址的映射关系,若无,则发起一次DNS查询
- 浏览器与服务器建立TCP连接(3次握手的流程)
- 浏览器在TCP连接中发送对应的HTTP请求内容
- 浏览器收到HTTP响应,若是短连接则直接关闭TCP,若是长连接则无需关闭,等待其他请求进行通道复用
- 浏览器检查响应,判断是需要重定向(3xx),错误(4xx或者5xx)
- 如果响应是可缓存的,则直接把响应缓存到本地缓存中
- 浏览器对响应进行解码处理
- 浏览器对响应结果进行渲染操作