
# 事务ACID
- 原子性(Atomicity):原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生;
- 一致性(Consistency):事务前后数据的完整性必须保持一致;
- 隔离性(Isolation):事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离;
- 持久性(Durability):持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
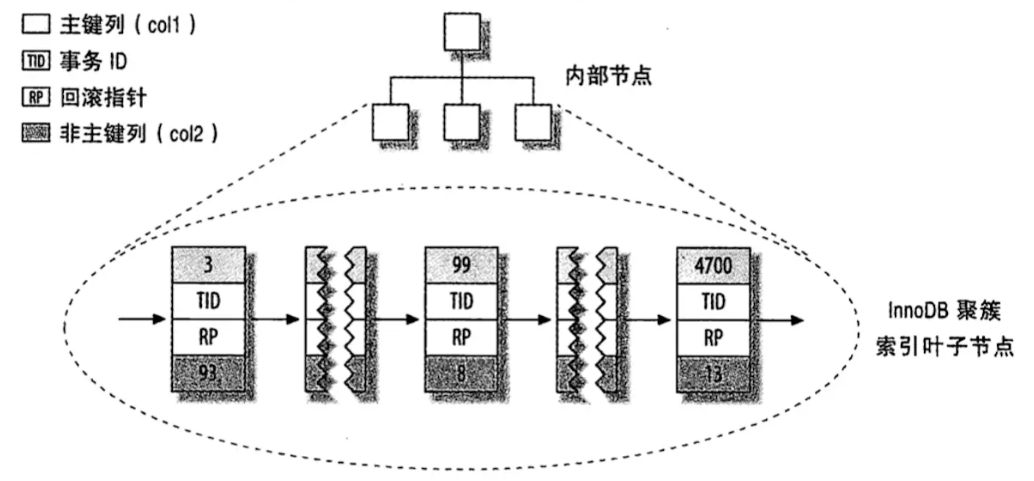
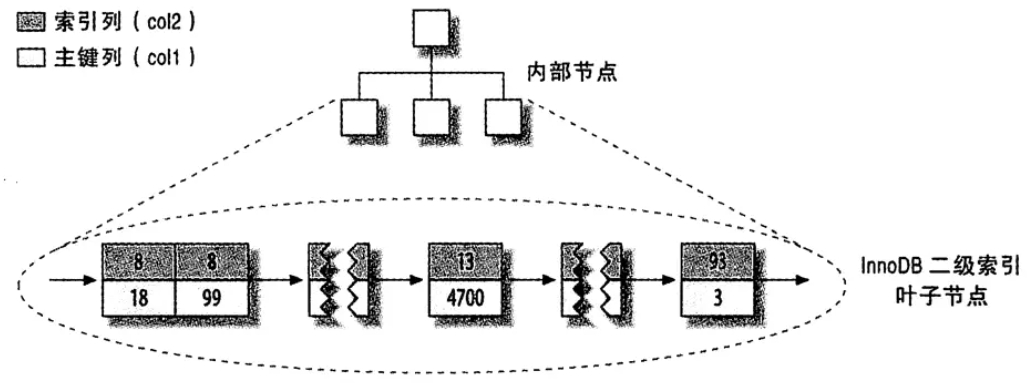
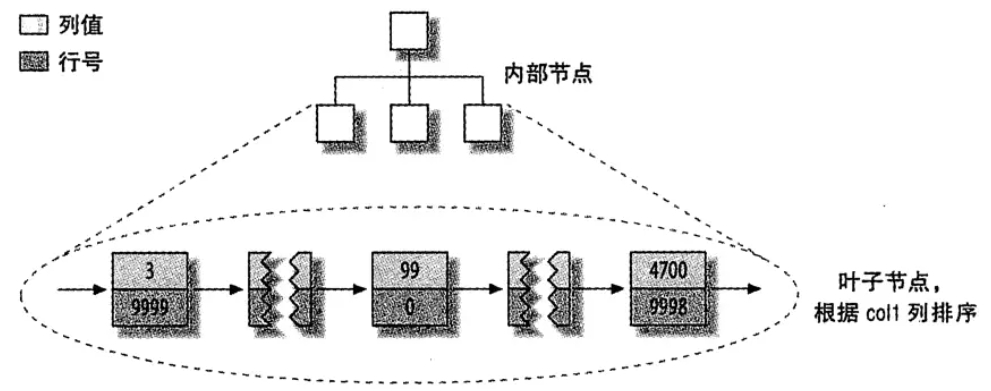
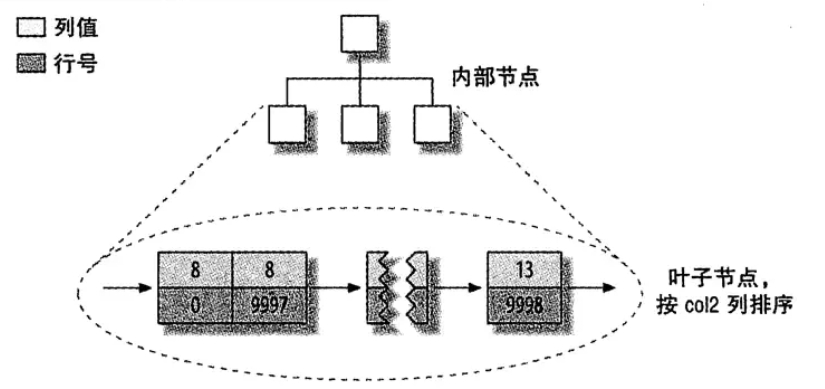
# 聚簇索引和非聚簇索引
- 非聚簇索引:表数据和索引是分成两部分存储的,主键索引和二级索引存储上没有任何区别;使用的是B+树,叶子节点存储的是索引值+行号
- 聚簇索引:表数据和主键一起存,主键和其他二级索引分开存;二级索引存储的是索引值+主键id
聚簇索引优点:
- 取出范围数据时候,性能更好,因为是连续的
- 聚簇索引将数据+主键索引放一起,如果从主索引查找数据会更快一些,因为直接读取即可
聚簇索引缺点:
- 严重依赖插入的顺序,如果不按顺序插入会导致页分裂
- 二级索引需要两次索引查找,第一次找到主键,第二次找主键所在行数据
# 事务隔离性
| 问题 | 描述 |
|---|---|
| 脏读 | 一个事务读取到了另外一个事务中没有提交的数据 |
| 不可重复读 | 在同一个事务中,两次读取同一行记录,结果不一样 |
| 幻读 | 在同一个事务中,同样select语句执行两次,返回的记录行数条数不一样 |
| 丢失更新 | 两个事务同事修改同一条记录,一个事务的修改被另外一个事务覆盖了 |
| 名称 | 解决问题 |
|---|---|
| RU(Read Uncommited)读未提交 | 最低的隔离级别,上述问题都没有解决 |
| RC(Read Commited)读提交 | 解决脏读 |
| RR(Repeatable Read)可重复读(mysql默认隔离级别) | 解决脏读、不可重复读 |
| Serialization串行化 | 解决所有问题 |
# 如何解决更新丢失的问题
利用单条语句的原子性:
在一条语句中直接修改数据:如直接update xxx set a = a + 1 where id = 1这种功能性的SQL,但是局限性很大,无法知道修改前a的值
悲观锁:
认为数据并发冲突概率很大,读取之前就上锁,利用select xxx for update语句,如果在悲观锁中事务出现问题,会造成死锁,并发性能很低
乐观锁:
认为冲突概率很低,等到回写时候判断是否被其他事务修改,一般使用version版本号+CAS的机制保证
# 各种DB的使用场景
| 引擎类型 | 特点 |
|---|---|
| InnoDB | 面向OLTP,默认的存储引擎,采用聚集方式存储;支持事务、行级锁、外键、XA规范和savepoint、支持全文索引 |
| MyISAM | 面向OLAP,非聚集方式存储(MYD:数据文件,MYI:索引文件),不持支事务,锁颗粒度为表级,支持全文索引 |
| Memory | 将表数据存放在内存中,默认使用哈希索引;速度快、锁颗粒度为表级、不支持TEXT和BLOB类型、存储varchar按照char的方式进行,浪费内存空间 |
| Archive | 只支持insert和select操作;对行数据进行压缩处理(1:10),适合存储归档数据 |
# 数据库的调优处理
- 原则合适的字段类型,没有负数的情况下尽量使用unsigned,尽量将列设置为not null;
- 利用join代替子查询,尽量使用inner join;
- 当只需要一条数据的时候,使用limit 1直接返回;
- 不能使用select *,把检索的目标字段显式地展现出来,而且避免在where中进行null值判断,否则会放弃索引导致全表扫描;尽量不要在where子句中对列进行函数处理,会导致索引失效;where子句中参数必须和列的类型保持一直,防止隐式转换;
- 建立合适的索引,在搜索中使用最左原则,而且把区分度高的字段排在前面,以提高对应的检索性能;
- 开启慢日志查询,对应的参数为slow_query_log=ON,设定对应的慢查询的阈值(秒)参数long_query_time,记录对应没有使用索引的语句参数log_queries_not_using_indexes=ON;
- 使用join的时候,注意防止字符编码不同导致隐式转换导致性能下降;
- 尽量使用覆盖索引,避免select出过多的字段数据;尽量使用扩展索引,如a已经有了索引,当前需要增加(a,b)索引,那么只需要修改原来的索引即可。
# MVCC
MVCC是"Multi-Version Concurrency Control"的缩写,对数据库的任何修改的提交都不会直接覆盖之前的数据,而是产生一个新的版本与老版本共存,使得读取时可以完全不加锁。这个版本一般用进行数据操作的事务ID(单调递增)来定义。MVCC大致可以这么实现:
- 每个数据记录携带两个额外的数据
created_by_txn_id和deleted_by_txn_id; - 当一个数据被insert时,
created_by_txn_id记录下插入该数据的事务ID,deleted_by_txn_id留空; - 当一个数据被delete时,该数据的
deleted_by_txn_id记录执行该删除的事务ID; - 当一个数据被update时,原有数据的
deleted_by_txn_id记录执行该更新的事务ID,并且新增一条新的数据记录,其created_by_txn_id记录下更新该数据的事务ID。
对于Read Committed,每次读取时,总是取最新的,被提交的那个版本的数据记录。
对于Repeatable Read,每次读取时,总是取created_by_txn_id小于等于当前事务ID的那些数据记录。在这个范围内,如果某一数据多个版本都存在,则取最新的。
# 锁相关的查询与命令
-- 查看死锁进程
show processlist;
-- 杀死进程
kill 123456;
-- 查看当前事务
select * from information_schema.innodb_trx;
-- 查看当前锁定的事务
select * from information_schema.innodb_lock_waits;
select * from performance_schema.data_lock_waits;
-- 查看当前等锁的事务
select * from information_schema.innodb_locks;
select * from performance_schema.data_locks;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 查询优化Explain
| 标志 | 简要描述 | 详细描述 |
|---|---|---|
| id | 选择标识符 | SQL执行的顺序id |
| select_type | 表示查询的类型 | SIMPLE:简单select语句 PRIMARY:子查询中最外层查询被标记为PRIMARY UNION:UNION中的第二个或后面的select语句 SUBQUERY:子查询中的第一个select语句 |
| table | 输出结果集的表 | 访问数据库表的名称 |
| partitions | 匹配的分区 | 匹配到的分区信息 |
| type | 表示表的连接类型 | ALL:全表遍历,一般是没有where查询条件 index:与ALL相似,进行索引全表扫描,一般是查询的字段列有索引 range:索引范围扫描 ref:非唯一索引连接匹配 eq_ref:唯一索引连接匹配 const和system:单表最多有一个匹配行,使用primary key或者unique索引查询 NULL:不用访问表或者索引(直接从缓存或者元数据中取出查询内容,如从索引列中选取最小值) |
| possible_keys | 表示查询时,可能使用的索引 | 查询涉及到字段上的索引,将该索引列出,但不一定被查询使用 |
| key | 表示实际使用的索引 | 实际使用的索引,可以使用FORCE INDEX、USE INDEX、IGNORE INDEX指定索引 |
| key_len | 索引字段的长度 | 使用索引的长度 |
| ref | 列与索引的比较 | 与索引的比较,表示连接匹配条件 |
| rows | 扫描出的行数(估算的行数) | 估算出结果集的行数 |
| filtered | 按表条件过滤的行百分比 | 满足查询记录数量的比例 |
| Extra | 执行情况的描述和说明 | Using Index:索引覆盖,不会回表 Using filesort:需要额外的排序操作,不能通过索引顺序达到排序效果,建议优化 Using where:查询时未找到可用索引,而通过where条件过滤获取所需数据 Using temporary:查询后结果需要使用临时表存储,一般在排序或者分组查询用到,建议优化 Using join buffer:联表查询时候没有用到索引,需要一个连接缓冲区存储中间结果 |
# 索引不生效的场景
- 列类型与查询条件的类型不一致;
- 使用like进行左匹配;
- 在查询条件中使用了or,需要将or的每一列都加上索引;
- 对索引列进行函数运算;
- 联合索引的顺序问题;
- 数据量太少,mysql认为全表扫描比使用索引更快。
# 慢SQL定位设置
-- 查看当前设置
SHOW variables LIKE '%quer%';
-- 开启或关闭慢日志
slow_query_log = ON
-- 慢查询的阈值,单位为秒
long_query_time = 5
-- 慢查询的记录文件路径
slow_query_log_file = D:\tools\MySQL\mysql-8.0.30-winx64\data\MinChiangHomePC-slow.log
-- 记录没有索引的SQL
log_queries_not_using_indexes = ON
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
慢SQL实验如下:
-- 执行一个长达10秒的SQL
SELECT
SYSDATE(),
SLEEP(10),
SYSDATE();
-- 不用索引执行一个查询
SELECT * FROM api_statistics as2;
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
查看D:\tools\MySQL\mysql-8.0.30-winx64\data\MinChiangHomePC-slow.log文件
TCP Port: 3306, Named Pipe: MySQL
Time Id Command Argument
# Time: 2023-06-19T14:40:07.646760Z
# User@Host: root[root] @ localhost [127.0.0.1] Id: 10
# Query_time: 10.013659 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1
use flink;
SET timestamp=1687185597;
/* ApplicationName=DBeaver Ultimate 21.3.0 - SQLEditor <Script-10.sql> */ SELECT
SYSDATE(),
SLEEP(10),
SYSDATE()
LIMIT 0, 200;
# Time: 2023-06-19T14:42:31.751546Z
# User@Host: root[root] @ localhost [127.0.0.1] Id: 10
# Query_time: 0.005397 Lock_time: 0.000015 Rows_sent: 1 Rows_examined: 1
SET timestamp=1687185751;
/* ApplicationName=DBeaver Ultimate 21.3.0 - SQLEditor <Script-10.sql> */ SELECT * FROM api_statistics as2
LIMIT 0, 200;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18